本文出自“Unity官方开发者社区”,Unity Open Day 北京站-游戏专场分享
微信、抖音、QQ、快手、支付宝、头条、百度等等都是国内的小游戏平台,以微信为例,其 2019 年 5 月已经实现了玩家数量过亿,2021 年流水过千万的产品已经超过 50 款。这些数据足以显现当下小游戏拥有强大的玩家基础以及变现能力,因此 Unity 正在逐步加大对移动端小游戏的支持。
Unity 中国引擎底层架构技术主管赵亮带来以 Unity 小游戏开发为主题的演讲,演讲中分别介绍了主流的小游戏平台及技术方案;即点即玩小游戏需要用到的资源流式加载 Auto Streaming;小游戏技术方案:Native Instant game 与 WebGL。
演讲中除了提供了极为实用的技术意见,还着重介绍了 Unity 引擎侧优化和改进,包括优化内存占用、优化绘制的效率、进一步给引擎瘦身、加快小游戏的启动速度。
以下是分享正文:
赵亮:今天跟大家一起聊一聊使用Unity开发小游戏。小游戏是一种嵌在宿主应用内部,无需下载安装,可即点即玩的游戏产品形式。国内小游戏用户规模庞大,2018年,小游戏市场达到300亿元规模,在移动游戏市场也是一个不小的占比,大概占到20%左右,因此Unity正在逐步加大对移动端小游戏的支持。
我的分享包括几个方面:首先,我们介绍一下当前主流的小游戏平台,以及他们采用的技术方案;接下来,介绍一下即点即玩小游戏需要用到的资源流式加载;然后,分别介绍两种小游戏技术方案:Native Instant game与WebGL;最后,介绍一下我们未来的工作方向。
小游戏平台
微信、抖音、QQ、快手、支付宝、头条、百度等等都是国内的小游戏平台,这里介绍比较有代表性的微信和抖音,以及采用的技术方案。
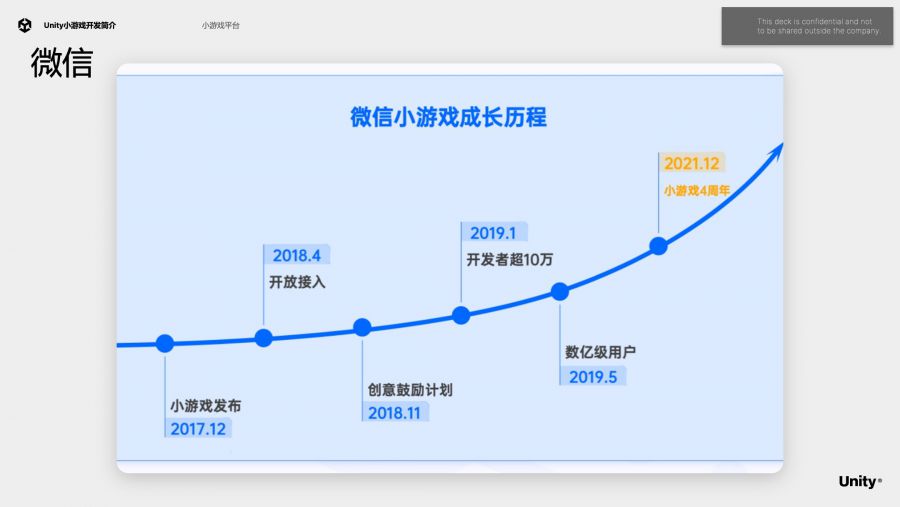
微信是2017年12月发布“跳一跳”小游戏,2019年1月起开发者数量已经超过10万,2019年5月用户过亿,2021年流水过千万的产品已经超过50款。
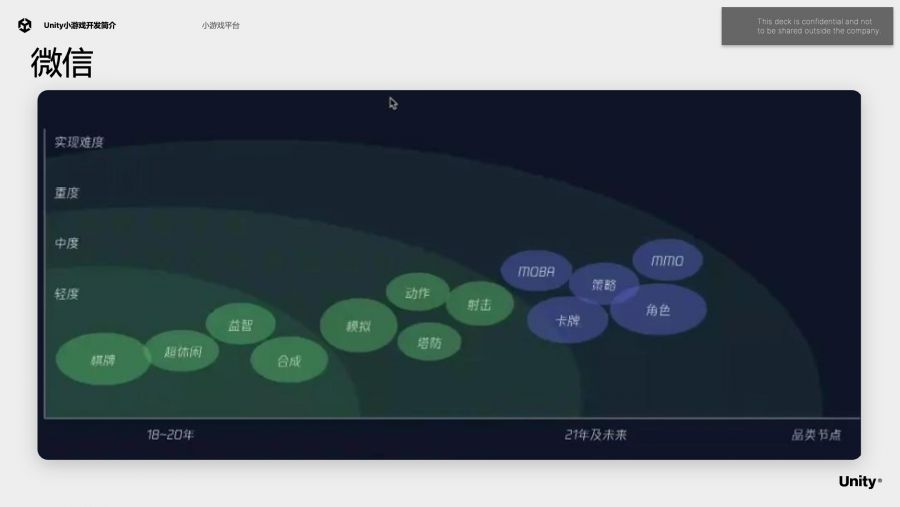
图中展示的就是微信小游戏的品类,随着时间的发展,我们可以看出小游戏品类近年逐渐从超休闲向中重度发展,例如MMO、策略游戏等也开始往小游戏平台发展。
大家也可以关注微信公开课,上面有些开发者分享使用Unity开发小游戏的经验。
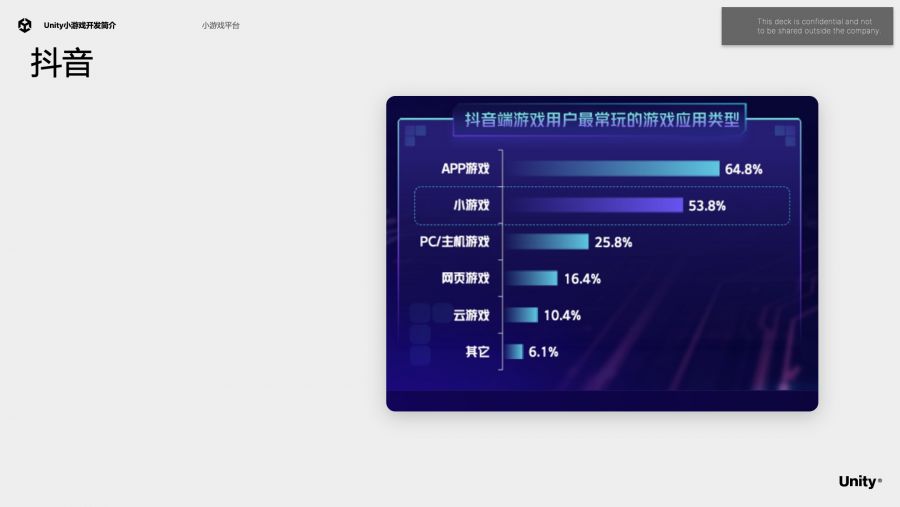
抖音平台经过调研发现,小游戏受欢迎程度仅次于APP游戏,同时小游戏用户规模较大,特征比较显著,大多是18-40岁的年轻男性,有不俗的消费能力。
在宿主应用中,实现即点即玩的小游戏主要有两种技术方案:
一种是基于浏览器内核,使用wasm+webgl的方案;另一种是在安卓上实现的native instant game。大部分小游戏平台都采用WebGL,但native instant game好处是游戏品质可以媲美原生APP,抖音和快手都在用这种方案。
资源流式加载
前面提到小游戏在从“超休闲”往“中重度”不断发展,小游戏中用到的资产越来越多。有些小游戏资产打包后有几百兆字节,甚至1GB以上。为了让玩家可以即点即玩,减少等待下载的时间,需要实现按需的流式下载。对于游戏开发者来说,管理好资源的流式加载需要投入不少开发时间。因此我们在引擎侧开发了AutoStreaming这个功能,让引擎底层自动处理好流式加载。
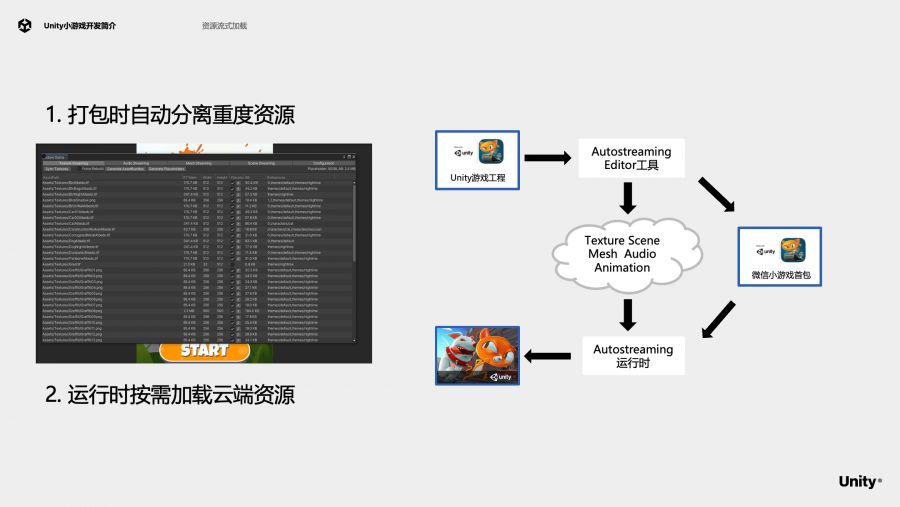
这里我们简单介绍一下AutoStreaming(自动流式加载)的工作原理。在Unity Editor里,我们提供了工具,可以在打包时自动分离出重度资源。诸如:Texture、Mesh、Audio、Animation、Font。这些资源将被部署到云上。分离出重度资源后,游戏的首包、游戏的AB包会大大减小,因此可以让小游戏快速的下载、加载。游戏运行时,引擎会根据需要自动从云上下载资源。开发者不用修改游戏的逻辑,可以像往常一样同步实例化prefab。这些texture,mesh会在一个后台队列里,自动被下载、加载。
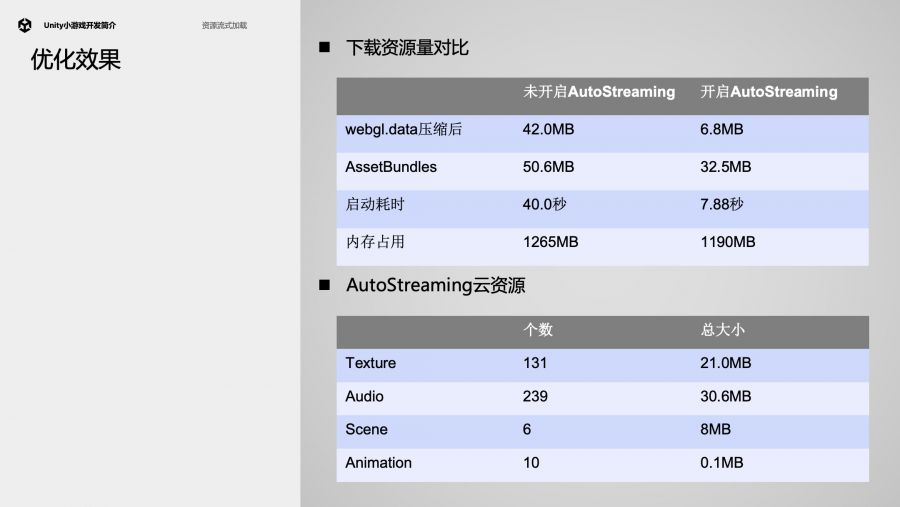
这里我们以一款线上的小游戏为案例,看一看AutoStreaming的效果:首包中的数据减少了很多,从42M降低为6.8M,因此大大减少了启动耗时(40秒降低为7.88秒)。用户打的AssetBundle也减小了一些,因为我们只选择了一部分贴图做AutoStreaming,所以瘦身程度不是很大。
另一处很重要的收益来自于内存,内存占用减少了75MB。内存对于iOS平台是很珍贵的。减小的原因在于被剥离的重度资源有更加合理的生命周期。未开启AutoStreaming时,这些纹理在加载后依然占用内存(首包内存orAB内存)。
这是webgl平台的一个特殊之处,它没有真正的文件系统,只有一个内存中的文件系统。首包里的资源会持续占用内存,AB在未unload前也会一直占用内存。这跟原生APP不一样,在原生APP中,每次读取文件中的一块,只要通过复用一小块内存就可以访问一个大文件。
Native Instant Game
简单介绍一下Native Instant Game方案:优点很明显,可以直接对标原生APP,性能一样,体验也是一样;支持多线程;支持Gles3、Vulkan;原生APP插件也都可以用。可以采用同步方式访问沙盒中的文件,访问效率比较高,占用内存也比较少;以独立的子进程运行在沙盒中,不会干扰宿主运行;稳定性和安全问题Native Instant Game也提供完整的方案。因此对移动游戏开发者来说适配Native Instant Game成本很低,只要进行流式加载,不需要额外的适配和优化。
右侧图是来自抖音平台的小游戏,叫做《古董就是玩儿》,我们曾经将其适配至WebGL平台,画质降低还是很明显的,所以这是Native Instant Game的优点。
当然了,它的缺陷也很明显,它目前还没法支持iOS平台。所以微信没有集成这种方案,字节、快手等其它平台采用混合方案。在iOS上采用WebGL方案,在安卓上既支持WebGL也支持Native Instant Game。如果有些游戏追求性能天花板更高,可以采用Native Instant Game;假设追求受众更多,游戏品质没有达到性能天花板上限,可以选用WebGL。
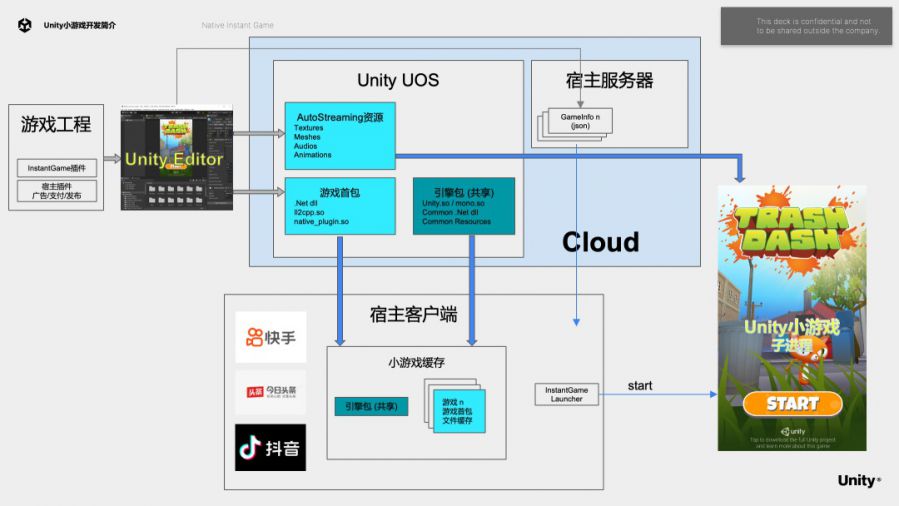
下图介绍的就是Native Instant Game工作原理。Unity把每个小游戏运行时都需要的运行时库、默认资源打包在一起,作为一个共享的引擎包,方便宿主APP提前准备,从而减少每个小游戏启动时等待下载的时间。共享引擎包大约有9MB,具体包含libunity.so,libmono.so等运行时库、通用的.net dll,如:mscorlib.dll System.xxx.dll UnityEngine.xxx.dll、Unity default resource。
有了共享的引擎包以后,开发者对小游戏平台进行打包,基本上打包成两部分就可以:首先是一个很小的首包,5-10MB左右,可以方便快速加载和下载,包含游戏本身的逻辑和第三方插件的so文件、AutoStreaming资源,以及一个json描述文件(游戏名称、首包下载url、引擎版本和下载链接、文件MD5),供开发者提审,以及客户端加载小游戏使用。
宿主客户端启动一个小游戏的时候会根据刚才提到的json文件描述拿到游戏首包。前面提到的共享引擎包,宿主通常都会提前下载和解压。然后客户端把首包解压到小游戏对应的沙盒文件夹,通过很小的InstantGame Launcher启动Unity小游戏子进程就可以了。
游戏运行的时候可以自动从云端下载这些所需的资源,这些是针对AutoStreaming的情况,否则用户需要自己动态加载。
webGL
下面我们详细介绍WebGL方案,优点是支持iOS和Android,但方案限制很多,我们会用更多的篇幅介绍。
WebGL在iOS平台上内存十分受限,低档机不能超过1GB,高档机大概1.4GB左右,超过这一限制可能就会触发操作系统OOM迫使进程重启。WebGL运行效率比原生APP慢3倍左右,目前只支持单线程不支持多线程,所以WebGL小游戏CPU性能比原生低不少。图形API只支持WebGL1/WebGL2,所以有些高级特性和优化没有办法使用,包括Compute Shader。没有文件系统,所以需要更大的内存模拟文件系统。这也导致Unity cache机制受到很大影响,cache文件无法被同步访问。
由于CPU侧性能比较弱,游戏复杂度提高、计算量增大的时候,手机很容易过热。也会对网络API有限制,因为只支持websocket,所以需要开发者进行适配。由于以上这些限制,导致能使用的插件也比较有限。iOS对于WebGL的支持也不尽如人意,我们经常要为iOS平台做特殊优化、写特别的workaround。
对于WebGL方案来说,iOS平台的问题比Android平台要多。因此接下来的讨论中,我们都关注如何在iOS平台上profile、优化小游戏。iOS平台优化好了,Android平台基本不会有问题。
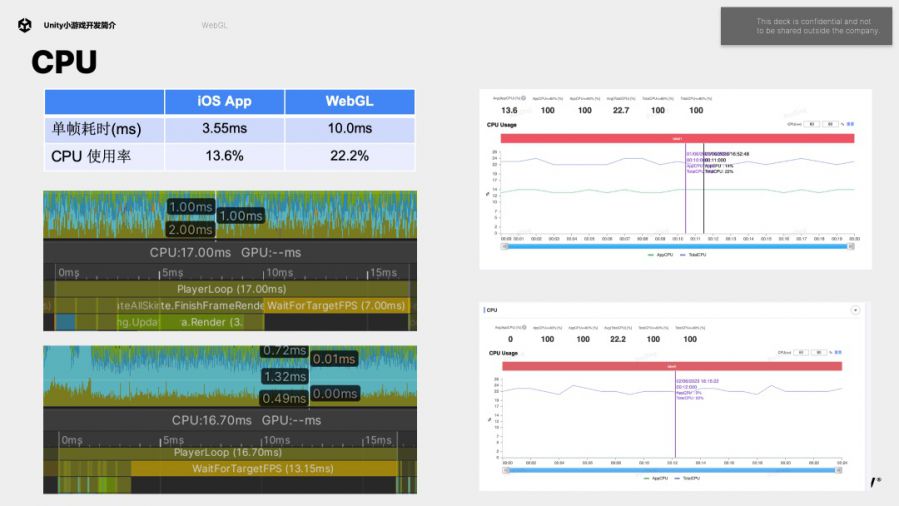
我们这里使用一个案例分别打包原生APP和WebGL小游戏,对比内存、CPU、GPU的差异。我们使用的测试手机是iPhone12。
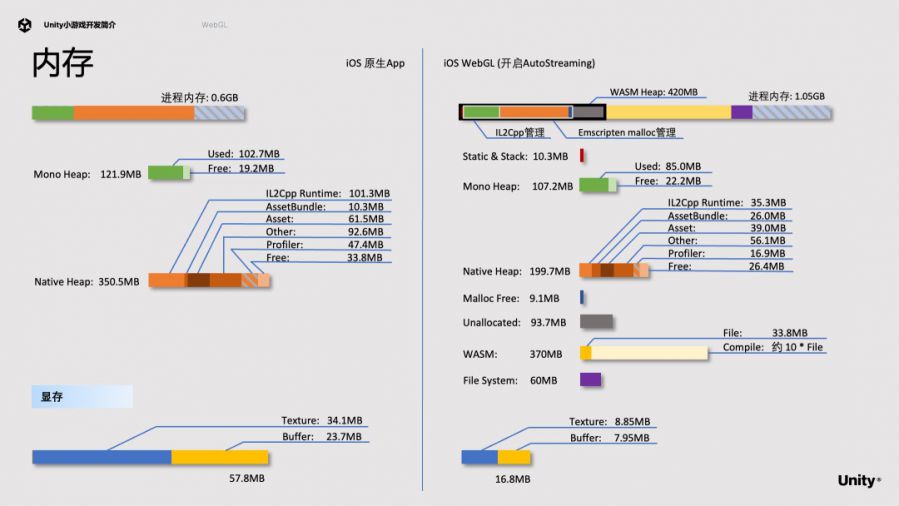
相比原生APP,WebGL进程内存占用多了450M左右,增大的部分在于加载和编译占到340M;Wasm heap有些Unallocated内存,多出来90M;File System多了60M。
除了Wasm文件本身之外,浏览器的内核在代码编译执行的时候也会产生更多的内存消耗,相关的缓存、JIT优化也会使用较多内存,总体大约是Wasm文件大小的10倍左右。
接下来分析Unallocated的部分。Wasm heap的大小是从一个预设值开始,然后以一定步长逐步扩容,扩容的方式比较傻,需要复制整个ArrayBuffer。例如从400M扩容到500M,扩容的时候400M也在,500M也在,总共会有900M的峰值。我们建议开发者根据游戏实际内存峰值,刚开始设立一个比较大的预设值。但这样会带来另外一个问题,就是会在wasm heap的尾部留有一段尚未分配的部分,就是90M的地方。
文件系统会多使用内存。浏览器的沙盒机制导致WebGL无法访问本地文件,为了浏览器安全,只能使用JavaScript + IndexedDB模拟一个文件系统。Wasm访问js层,js层再访问IndexedDB,这里js层会占用一定内存,不能像Native文件系统那样直接使用一小块内存访问大的文件。
还有一处值得注意的是Mono Heap和Emscripten malloc的空闲空间。WebGL上,Mono Heap由IL2Cpp分配管理,其他native内存(包括引擎Native Heap和其他第三方库如Lua分配的内存)由Emscripten的malloc分配管理(默认使用dlmalloc)。这两部分都是只增不减,而且相互独立,空闲空间无法共享,因此需要各自都注意控制峰值。
我们看到WebGL相比原生APP也有一部分内存占用减少,比较显著的就是Native Heap中的IL2Cpp Runtime。通过延迟加载meta信息、使用Sparse HashTable等方式使内存从101MB降低到35.3MB。这里主要是针对WebGL平台进行优化,后面会详细介绍这些。Asset相关的部分也有降低,因为资源压缩格式进行了调整,来自引擎底层内存分配器的行为和策略在不同平台上也有不同。
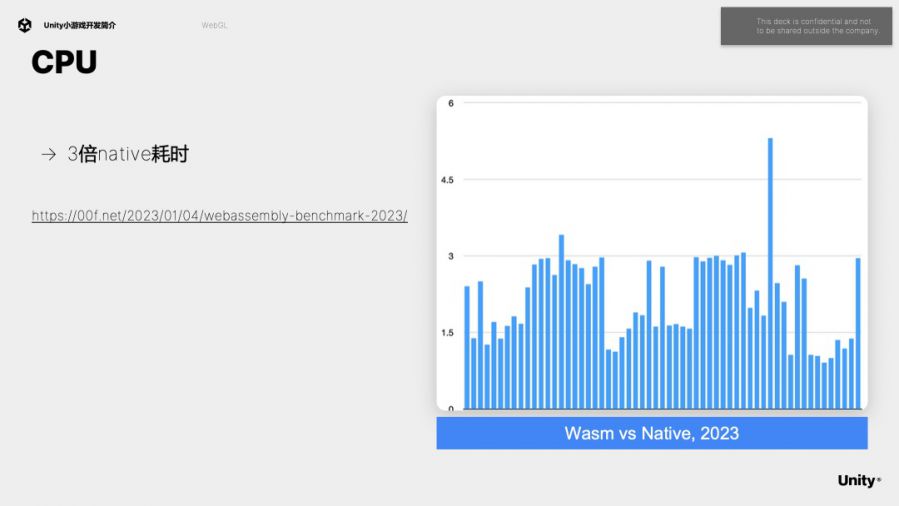
再来看一看CPU计算性能的对比。之前网上看别人的Benchmark研究,webassembly的执行效率约为原生app的三分之一左右。
我们拿了一款真实的小游戏进行测试。Timeline Profile可以看出原生APP耗时3.5毫秒左右,小游戏耗时10毫秒,所以整体来看WebGL的CPU性能与原生App相比相差3倍左右,其中既有WebGL单线程的原因,也有wasm本身执行效率的问题,印证了之前Benchmark结果。
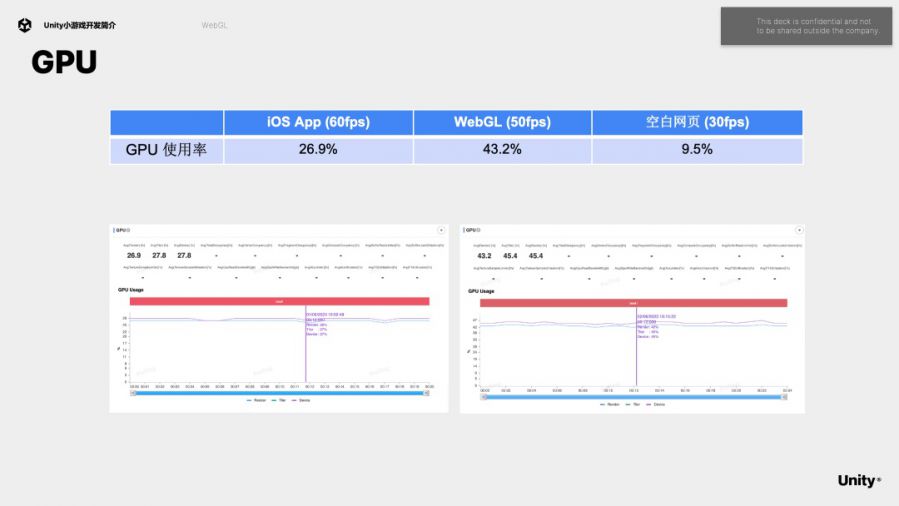
再来看GPU的对比,去除空白网页本身的GPU消耗以外,对一个游戏来说,WebGL和原生APP差距并不大,我们可以认为WebGL小游戏的GPU性能和原生APP差不多。
WebGL小游戏的开发和移植最近几年已经有大量的成功案例,所以新进来的开发者不用很担心,之前踩过的坑都已经处理好了。Unity有一个官方QQ群,大家如果有什么问题可以在群里聊。微信为WebGL小游戏开发也整理了很详尽的教程,公开课也有开发者分享使用Unity开发小游戏的经验。
为了减轻WebGL平台限制对小游戏开发的影响,我们在引擎侧也有很多优化和改进,包括优化内存占用、优化绘制的效率、进一步给引擎瘦身、加快小游戏的启动速度。
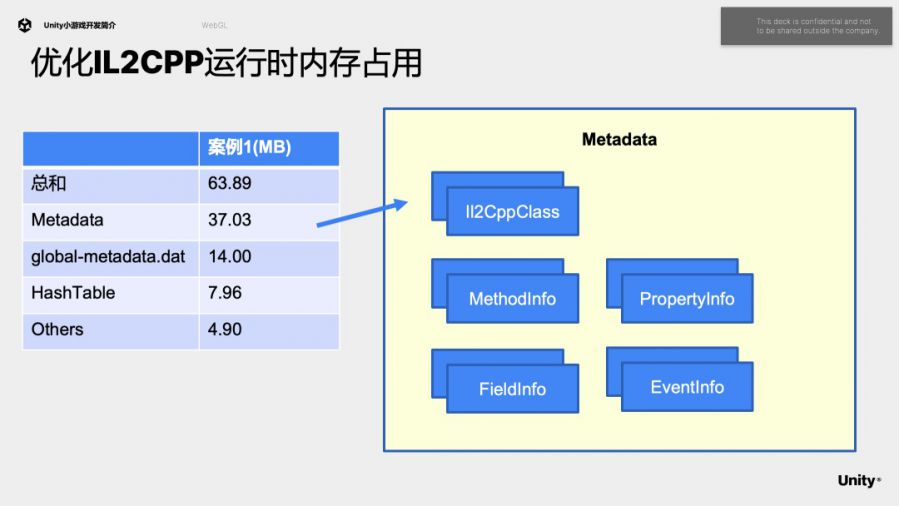
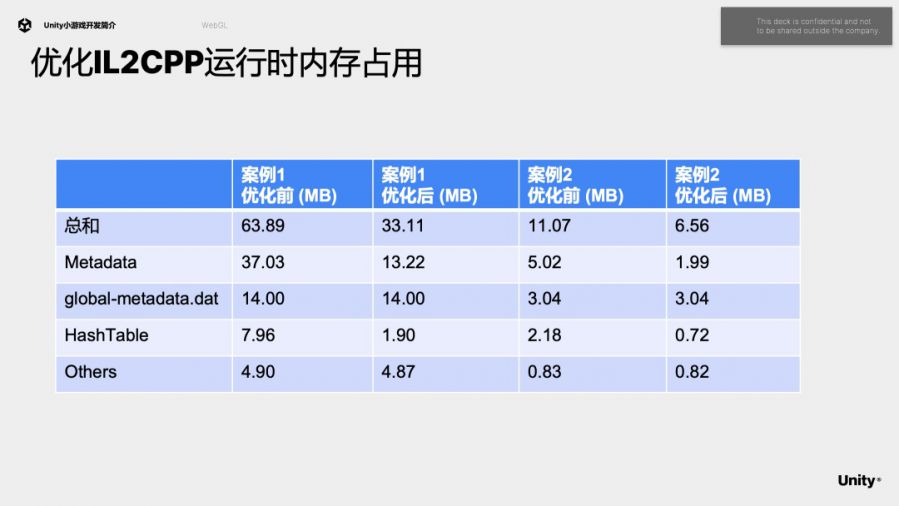
在一个案例中IL2CPP运行时内存占用从64M优化到了33M。也有优化DynamicVBO pool的复用机制,测试案例中从59M降低到了38M。后面提到的代码轻量化和资源裁减也会帮助减少运行时的内存占用。
这里我们详细介绍一下IL2CPP运行时内存的优化。我们首先分析一下IL2CPP运行时主要的内存开销。首先是Metadata,它是运行时构建的元数据结构,里面主要是Il2CppClass和它的各种成员变量。然后是global-metadata.dat,它是打包时生成的元数据序列化文件,在webgl平台会完整地加载到内存中。再是HashTable,用来在运行时加速元数据的访问。
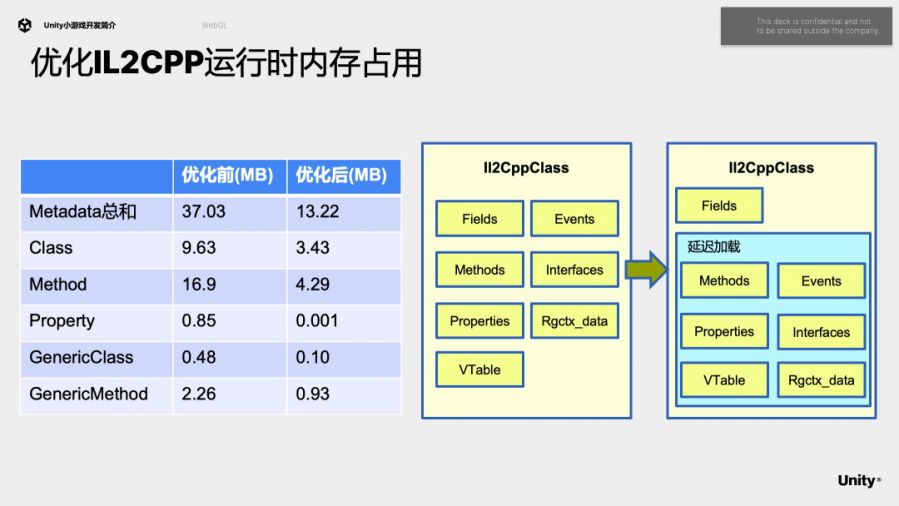
接下来,分析一下对Metadata部分的优化。这里主要是针对Il2CppClass及其成员变量的延迟加载,其中MethodInfo占比最大。之前的libil2cpp实现中,在使用到某个类型时,会初始化这个类型完整的元数据:包括它的所有函数、接口、事件、属性、虚函数表等等信息。但分析发现,脚本代码运行时,通常只会用到很少的一部分元数据(在反射或虚函数调用时访问)。例如:数组类型,它有155个方法,25个虚函数,实现了6个接口,但实际在运行时只会用到其中的很小一部分,存在冗余加载的情况。因此我们的优化思路是延迟加载这些元数据,等到真正需要某个元数据项目时才去初始化这份数据。
图中可以看到,除了Field之外的信息都可以进行延迟加载(Field信息在构建对象实例时就需要,它决定了对象实例的的内存布局)。延迟加载粒度可以精确到逐个方法的粒度。延迟加载也会带来一个比较小的开销,就是在访问某个元数据前需要做一次非空判断,目前我们还没有Profile出它引入的性能回退。
我们根据两个实际案例对比优化前和优化后的内存占用,63.8M降低到33.2M,11M降低到6.5M。除了MetaData的内存降低,HashTable也有降低,因为我们用sparse哈希表替代了dense哈希表。未来我们还会优化global-metadata.dat这个序列化文件。它里面包含大量string,有一部分可以用hash值替代。它里面还有大量索引使用32位保存,这也比较浪费内存。
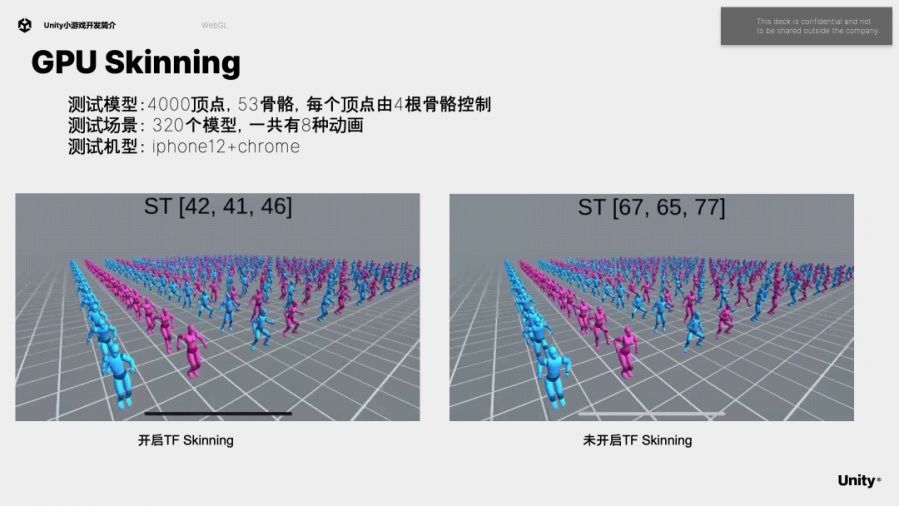
除了内存优化以外,我们也在绘制方面做了很多优化工作。WebGL不支持Compute Shader,这里通过Transform Feedback支持了GPU Skinning。优化Shader Compiler,将non-const global变量移到main函数中,帧率可以从23帧提高到55帧。修改Immediate Const Buffer转换过程,声明成const并赋予一个初始值就可以将某案例从32FPS优化到37FPS。我们还会提供可配置的max visible lights值,改成16甚至更小以后性能会有很大提升。iOS平台对WebGL的支持不够好,所以我们也针对iOS平台做了特殊的Workaround,避免使用过多的Uniform变量。在iOS14.x-15.4的WebGL上有一个Bug,针对这些版本,我们对同一个Canvas不共享IB和VB,可以改善UI渲染性能。
可以看到打开GPU Skinning以后平均每帧消耗42毫秒左右,没有开启的话每帧需要消耗67毫秒左右。
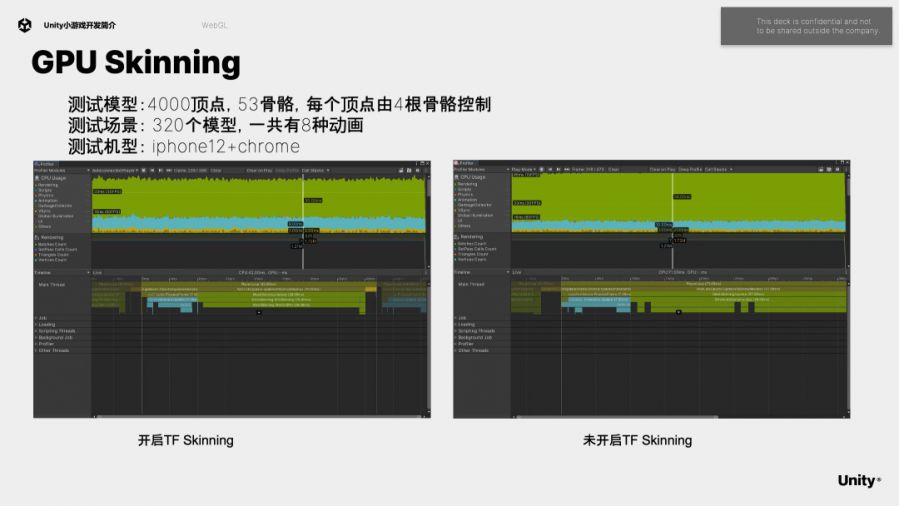
从下图中的Timeline Profile,可以看到MeshSkinning.Update时间开销从57ms降低到了29ms。
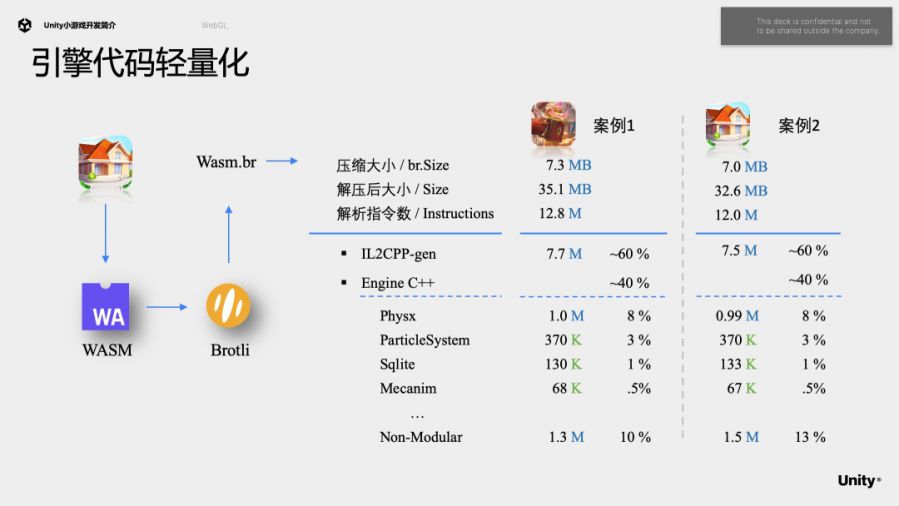
看一看引擎代码的轻量化。从前面的内存分析可以知道,30多M的wasm在加载后会占用300多M的内存,因此生成的wasm越小越好。之前Unity的方法主要是Managed Code Strip和Engine Code Strip,它们是通过静态分析依赖的方式做的strip,以函数作为颗粒度。我们在这里会更加深入地分析打包生成的wasm代码,看看除了这两个Strip,我们是不是还有更多的优化空间。
我们分析两个案例。游戏指令数都是1200万左右,其中il2cpp占比约60%,其余是引擎C++代码,占比40%,然后我们按模块对其进行分类,发现其中较重的模块有 Physx, particle system, sqlite, mecanim等,如Physx占了 8%。
通过分析,目前发现的问题有:案例2是一个消除类游戏,并未使用到什么Physx仿真,仅仅在UI上使用了Physx的射线检测,就引入了一个庞大的Physx库,所以是非常不合理的。Wasm中有很多模版展开的代码,拿空间换时间可能在某些平台上是比较不错的策略,但WebGL平台内存特别紧张,所以在WebGL上并不是一个好的策略。
目前我们做了的工作有:将一部分c++模板参数改为函数参数,减少生成的代码量;用宏剔除 webgl项目用不到的模块和函数,例如:Sqlite,ComputeShader,Physx的部分功能。未来我们还会继续清理启动流程、主循环里面不必要的步骤,以及探索如何优化il2cpp代码生成。
在加快启动速度方面,我们主要做了两件事情:一是跟平台合作,让平台提供中文字体,避免每个小游戏都在首包里放一个中文字体,可以节省5-10M左右的下载时间。二是动态裁减Unity Default Resource,这些资源不见得每个小游戏都会用到。目前看来对大部分游戏可以把Default Resource从3.5M降到400K左右。之前我们还尝试通过wasm snapshot方案进行加载。
未来工作
接下来聊一下未来工作的方向。除了前面提到的给global-metadata.dat瘦身、探索如何减少IL2CPP代码生成,主要有多线程和WebGPU这两大块。我们还会探索Web Assembly上的SIMD,甚至尝试让WebGL平台支持Burst。
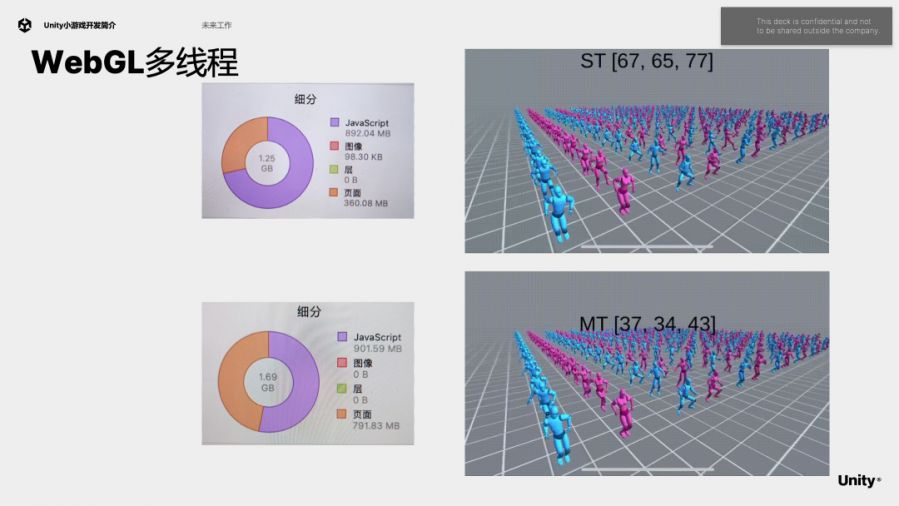
Unity现在已经可以打开WebGL多线程,可以看到打开多线程以后,DeformSkinnedMeshJob从主线程转到了web worker上。
这里还是针对之前的测试案例尝试使用多线程,使用后每帧消耗从68毫秒降低到38-40毫秒左右。
但是目前Unity多线程还不够稳定、不够完善,切换场景的时候可能Crash,目前也不支持RenderThread,因为web worker无法访问DOM。打开多线程以后,内存增加也比较厉害。另外WebGL多线程只能支持Native代码,不支持C#代码,也是我们要努力解决的问题。
四月底发布的Chrome 113已经支持WebGPU了,目前我们也是一边集成一边研究如何重构GFX Device的接口层,使它更接近于现代图形API,从而能够更多地发挥WebGPU的性能优势。
今天介绍到这里,谢谢大家!
来源:Unity官方开发者社区






 Steam
Steam  App Store
App Store 























 闽公网安备 35020302034348号
闽公网安备 35020302034348号