随着大数据时代的到来,对海量数据进行数据分析,并依据分析结果进行精细化运营成为各大企业的重要课题。但大数据行业门槛高,自建平台成本高、难度大、效率低,因此企业越来越需要专业的大数据分析工具。
针对市场需求,数数科技基于Hadoop、Presto、Kudu、Kafka等底层大数据组件,研发了一套企业级的海量数据即席分析系统——Thinking Analytics,简称“TA系统”。
TA系统颠覆了传统的大数据分析模式,从根本上解决了企业在海量数据分析上的痛点,能帮助企业真正将大数据分析在内部落地,实现精细化运营。
针对每天百亿级别甚至更大级别的数据量,TA系统可以做到秒级查询、秒级延迟。TA系统极大地降低了企业数据分析的成本,让大数据分析的大规模应用成为可能。
一、TA系统高可用架构概述
数数科技自创立以来 ,始终坚持「客户为本」。如何最大限度地提高TA系统的可靠性,使其在极端情况下仍能保障使用,全面提升用户体验,是我们必须解决的问题。
对此,我们决定:除了已拥有的一整套自动化运维系统外,更需要推出一套用户行为分析领域独有的、支持私有化部署的高可用架构方案。
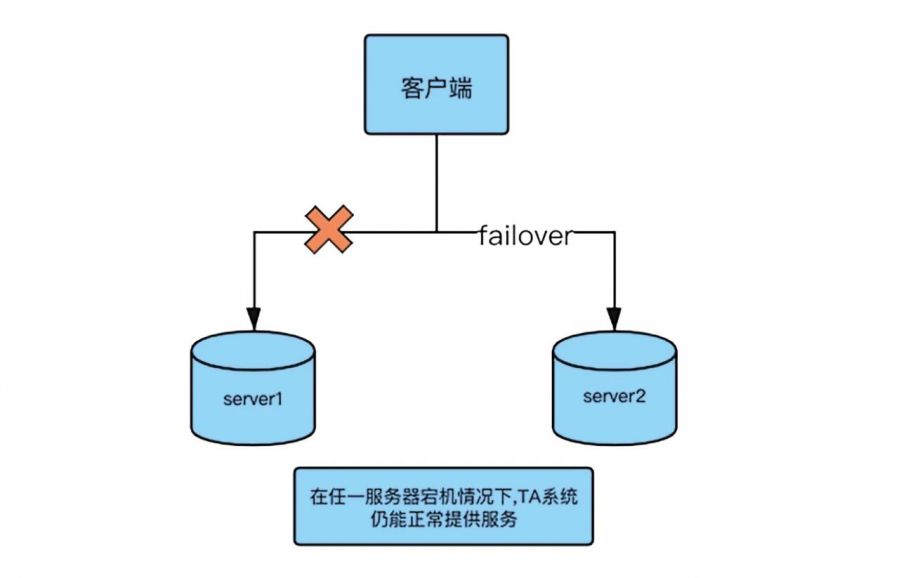
TA系统高可用架构图如下:
什么是高可用(HA)?简单来说,就是在服务器有硬件故障的情况下,服务仍然可用。换言之,该系统在组件或者服务器宕机的情况下仍然可以正常使用,从而极大地减少系统无法提供服务的时间。
TA系统的高可用,是指在任意一台服务器宕机或主动停机的情况下,TA体系保证其不影响集群的稳定运行和对外服务——即用户无感知,同时该服务器恢复后可以自动加入集群HA体系,解决了原先存在的单点问题,使得TA系统的可靠性得到质的提升。
二、TA系统高可用个性化配置组件
也就是说,高可用提供了一套极佳的可靠性保障机制。但不同的客户,需要的可靠性保障是不一样的。
有些客户的可靠性保障要求很高,要求在任何极端情况下都需要用户无感知;有些客户的可靠性要求比较低,只要数据存储不丢失即可。
因此,我们划分了不同的的可靠性等级,TA系统对不同的等级提供不同优先级的可靠性保障:
- 存储可靠性保障(最优先的保障,保障数据存储不丢失)
- 收数可靠性保障(数据能完全收入到TA系统,保障数据上传始终在运行)
- 自动化运维可靠性保障(保障TA系统出现故障时有能力自动恢复)
- 查询可靠性保障(保障TA系统页面始终能够访问,不会出现查询不可用)
- 数据流入可靠性保障(保障TA系统数据始终能够流入,不会出现数据流入延迟)
为方便客户根据上述可靠性级别,结合自己的实际情况和硬件成本,进行高可用架构的个性化适配,TA系统提供了组件级可配置化的高可用方式。TA系统的每个组件,客户都可以选择高可用版本或非高可用版本,并通过配置化的方式,一键部署。
那么,100%高可用架构的TA集群意味着什么?
- 任一节点的crash,不影响集群的正常使用
- 所有组件支持配置化的方式部署HA版本
- 硬件成本+集群可用性的个性化适配
同时,高可用架构除了支持配置化管理,可一键部署非高可用架构或高可用架构的TA系统外,为方便客户的使用和升配,也为每个组件提供了一键式的从非高可用架构平滑升级到高可用架构的命令。
总结起来,我们对TA系统的要求——保证高适配性、一键部署、一键升配、简单易用。
三、TA系统高可用架构技术实现
对于TA系统高可用架构的实现,我们遵循的原则是:先易后难,先重要再次要,逐个实现组件的高可用,并做好配套措施的路线图,从而实现整体集群的高可用。
对于TA系统的存储组件,比如Hadoop、Kudu,以及中间件Kafka等开源组件,它们是有官方的高可用版本的,我们只需要采用其官方版本即可。
// 3.1 MySQL高可用的实现
现在比较成熟主流的MySQL高可用解决方案主要有两种:一种是MHA,一种是MGR。
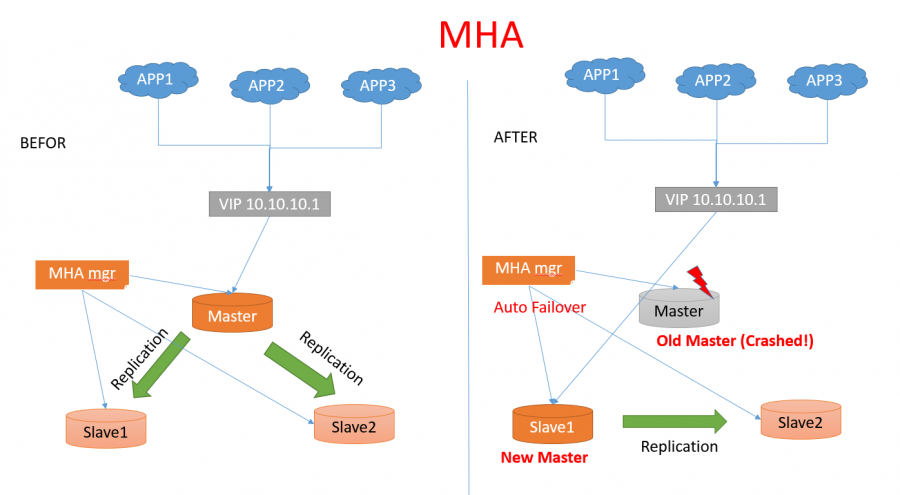
MHA:Master High Availability,是外部的基于MySQL主从半同步开发的一套高可用切换方案,对MySQL主节点进行监控,通过监控自动切换程序可实现自动故障转移至其他从节点,并提升某一从节点为新的主节点,其基于主从复制实现。目前,MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,另外两台充当从库。
MHA的缺点:因为它是异步复制,当主节点crash、故障自动转移的时候,并不能保证数据的完整性,可能丢失数据。
鉴于MySQL中储存的是最最重要的元数据,且TA系统必须保证在各种极端情况下不丢失数据。TA系统高可用,不能接受因高可用而导致数据的可靠性下降,所以MHA并不适用我们的高可用方案。
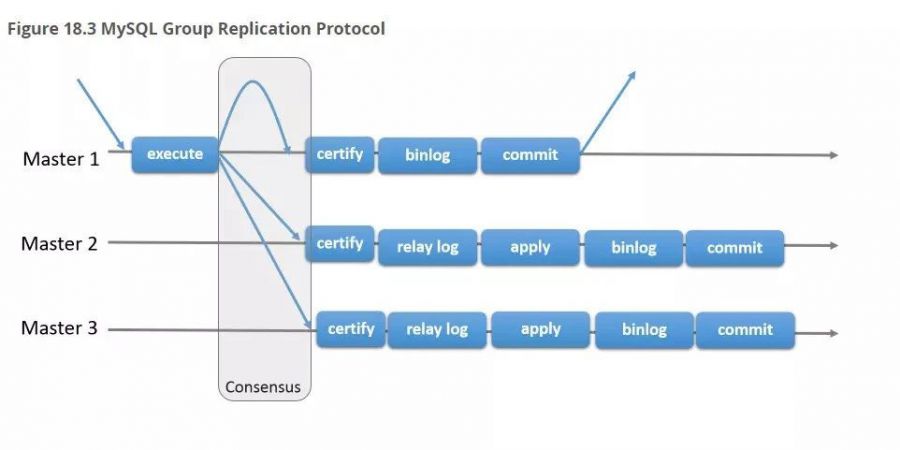
MGR:MySQL Group Replication,MySQL组复制是MySQL官方最新推出的shared nothing方案,其内部基于paxos算法,可以保证数据的强一致性。
MGR(MySQL组复制)是根据GTID来保证MySQL集群的强一致性,并且已经在美团、京东等公司的实际生产环境中成功应用。
但MGR有很多限制,所以需要在调研可行性的时候,研究它是否可以被TA系统采用。
MGR分为单主和多主模式:
- 单主模式分主从,其中只有主节点可写。
- 多主模式中任意一个节点都可写。
- 单主模式比较重要的限制是,推荐使用 READ COMMITTED 隔离级别来避免使用Gap Locks,每张表里必须要有主键或者非空的唯一键等。
- 多主模式除了上述限制外,还有诸如不支持外键级联操作等其他限制。
我们TA系统有很多关于外键的应用,所以只能采取单主模式。
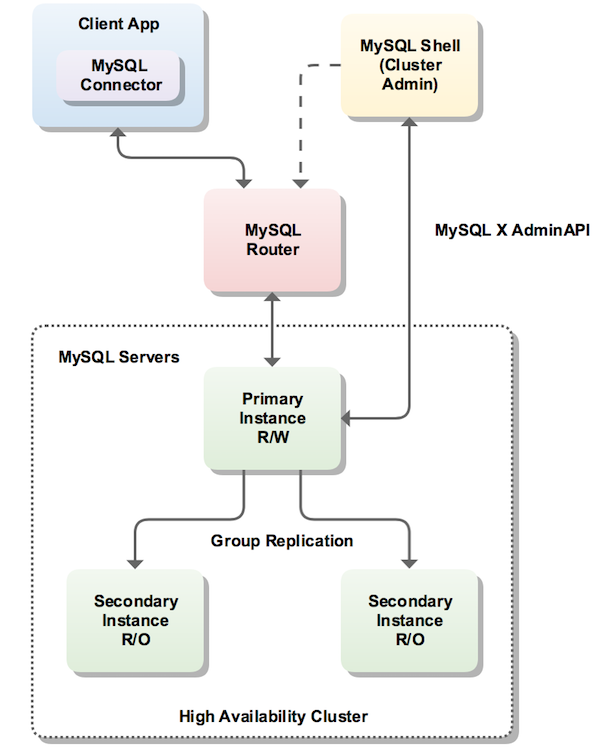
MySQL官方在MGR(MySQL组复制)的基础上,增加了一层代理层(MySQL Router),组合成MySQL InnoDB Cluster,这样,MySQL Router可自动进行failover操作,它的结构相比MGR更合理,我们最终采用的,也是MySQL InnoDB Cluster方案。
除了MySQL InnoDB Cluster,MySQL官方还推出了一个MySQL NDB Cluster,但它的代价很大,需要替换底层引擎,我们没有选用。
我们原先集群用的是MySQL 5.6版本,MySQL InnoDB Cluster是从5.7版本开始有的新特性,MySQL 5.7版本的InnoDB Cluster有一个问题,就是当三个节点的MySQL,其第一个节点退出组复制集群后,不会自动加入集群,所以需要在监控运维层增加一个重新加入组复制集群的操作。
我们在测试环境跑MySQL集群的时候,碰到了集群不稳定的问题。我们在测试中发现,一旦MySQL集群中的一个从节点下线,它将再也追不上主节点,一直处于recover状态。原来,默认情况下,MySQL的从节点是根据库粒度来并发回放relay log的,也就是从节点一个库一个slave thread线程去读relay log来回放日志的,我们需要加上slave-parallel-type=LOGICAL_CLOCK这个参数来支持同一个库下,多线程并发的执行relay log的回放。
// 3.2 Presto高可用的实现
我们使用的Presto是PrestoSQL版本,2020年底,PrestoSQL因为版权问题,已重新命名为Trino,但Presto这个名字更广为人知。所以为了不引起歧义,我们还是在下文中统一使用Presto来命名PrestoSQL/Trino。
Presto的高可用实现更加复杂,下面先介绍一下Presto的组件和架构设计:
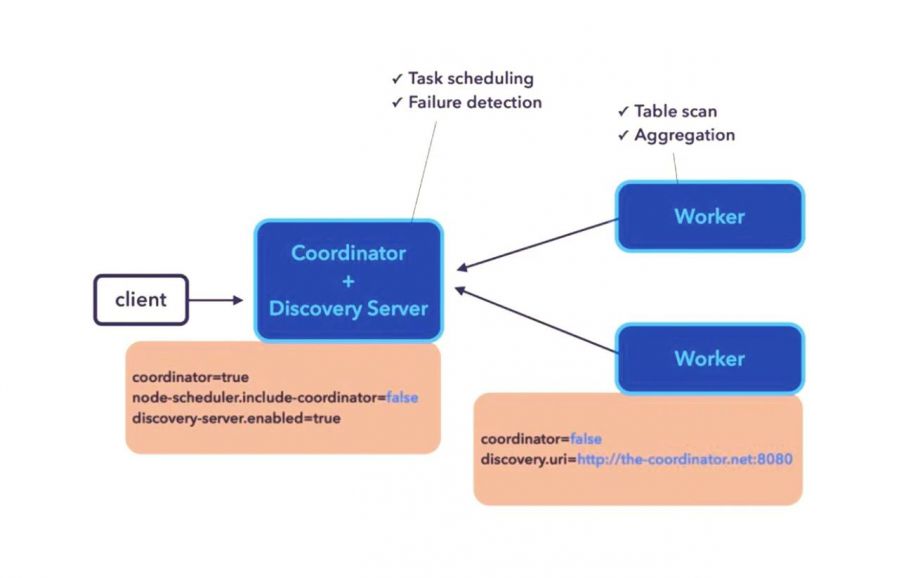
Presto包含三类角色:Coordinator、Discovery Server、Worker。Coordinator负责query的解析和调度,Discovery Server负责集群的服务发现,Worker负责执行计算。
Worker节点启动后向Discovery Server注册服务,Coordinator从Discovery Server获得可以正常工作的Worker节点。
在运行SQL的时候,由client端提交SQL查询,也就是一个http POST请求。然后该请求发送到Coordinator后,经过词法解析和语法解析,生成抽象语法树,并最终形成执行计划,下发到Worker端进行执行。
Presto的这三类角色可以自由组合,Coordinator、Discovery Server和Worker可以放在一个进程里,也可以彼此分开。不过一般来说,Coordinator和Discovery Server是放在同一个进程中的。
Worker可以理解为计算节点,也就是Worker本来就可以部署多个,由Coordinator进行管理。
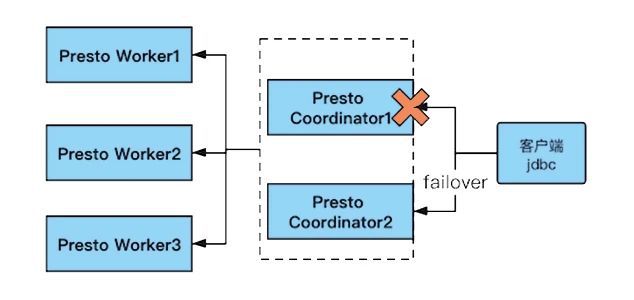
Presto的高可用主要解决的是Coordinator/Discovery Server的单点问题。
Presto高可用的解决有很多种方案,比如用HAProxy+Keepalived或者云服务商提供的lb这样的外部组件,但问题是这样就需要用VRRP这类虚拟IP来解决单点问题,而我们尽量要做到集群内部组件不依赖外部组件,这样从架构上来说,系统复杂度最低,也最容易维护。
综上,我们需要修改Presto底层源码来解决。
Presto的discovery其实就是airlift discovery,通过阅读源码,发现其内部是支持HA的,只是Presto的官方文档上没有展示出来。
对于Coordinator,社区也做了很多努力,比如把dispatcher模块拆分等等。
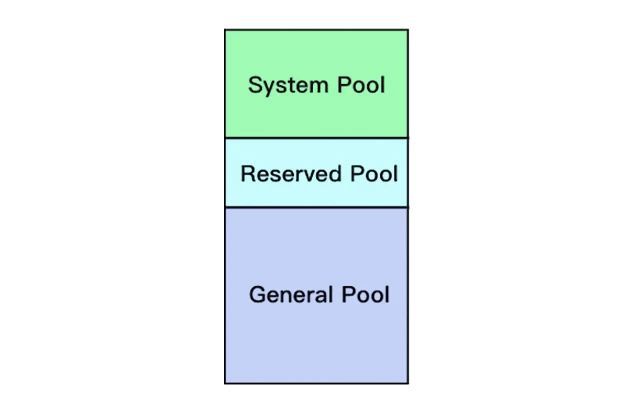
Coordinator做高可用如果不考虑shared queue的话,它最大的问题是内存管理。Presto采用逻辑的内存池,来管理不同类型的内存需求,把整个内存划分成三个内存池:System Pool 、Reserved Pool、General Pool。
System Pool 是用来保留给系统使用的。Reserved Pool和General Pool 是用来分配query运行时内存的。一般情况下使用的是General Pool。但是当有一个大query的时候,会使用Reserved Pool,防止大query发生饿死情况。
如果我们做高可用,等于集群中有2个Coordinator,他们同时管理Presto集群的内存,会造成内存管理混乱,并导致资源死锁。
通过分析这部分的源码,发现问题主要在Reserved Pool上,而且官方最新版的Presto也开始允许将Reserved Pool关掉,并把它改为默认值,因为大query饿死的情况非常少见,而且一般这种情况即使开了Reserved Pool,也很容易OOM,所以Presto集群这样设置,在实际使用效果上,反而更好。
我们结合TA系统的实际情况关掉了Reserved Pool,并经过测试,发现Presto集群可以同时运行2个Coordinator。
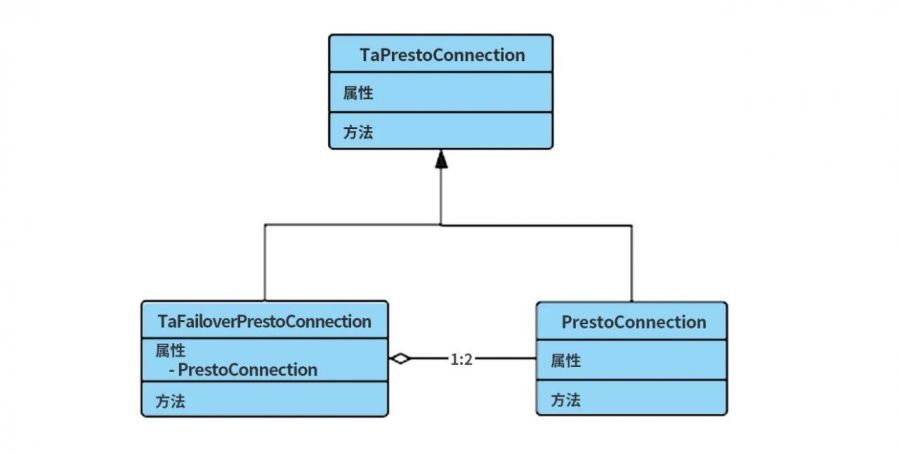
我们最终需要改造presto-jdbc源码,增加一个presto failover协议,也就是在原先的Presto Driver的基础上,增加一个TaFailoverPrestoDriver驱动类,使其支持故障切换功能,从客户端入手,解决Presto高可用的故障自动转移功能。
presto-jdbc内部由PrestoConnection类调用presto-cli的http接口,来流式地获取数据。
在具体的代码实现中,我们用了java经典的组合设计模式,在TaFailoverPrestoConnection这个最重要的实现类中,包含了主PrestoConnection和备PrestoConnection,并实现了他们之间的failover。
这样,我们在所有的方法实现中,调用current PrestoConnection中原先的方法即可,而不用太考虑里面具体的实现,这样大大简化了代码的冗余。
同时,我们改变原先的继承关系,让TaFailoverPrestoConnection和PrestoConnection都继承TaPrestoConnection接口,从而在一些反射调用中,做到presto单机协议和presto failover协议的兼容。
最后,官方Presto的SystemConnector在处理多个Coordinator节点的时候,会有Unknown transaction ID的问题,我们已经将其修复,并将多Coordinator节点的测试代码提交给了社区,被社区合并。 ( https://github.com/ prestosql/presto/pull/6328)
// 3.3 Redis高可用的实现
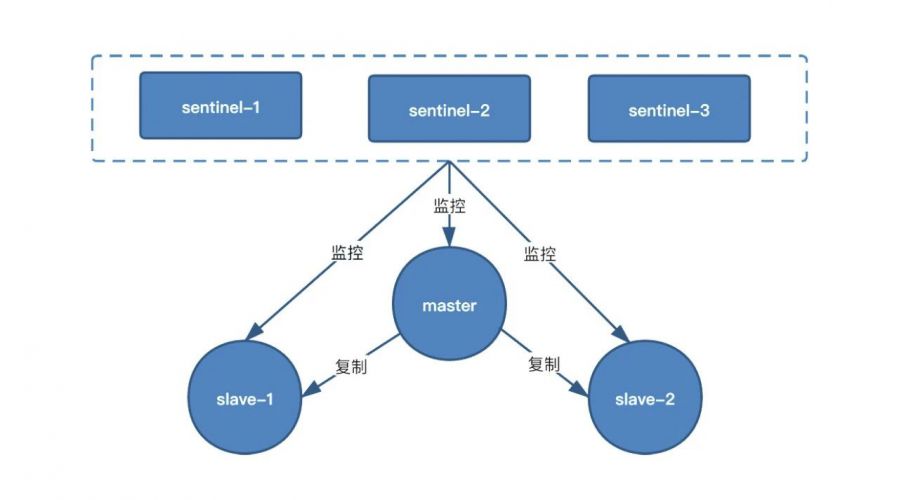
Redis我们采用Redis Sentinel来实现高可用,在实践过程中,因为TA系统的Redis中存有分布式锁,所以必须考虑分布式锁的数据一致性问题。
Redis作为分布式锁和数据缓存组件,提供了如下方案:主从复制模式、哨兵模式、集群模式。在高可用方案调研过程中,我们发现Redis社区在可用性和数据一致性的方向上,把可用性作为更高需求来作为高可用的解决方案。
我们曾经尝试过用Redis红锁的方案来实现高可用,但因为该方案实现不了强一致性而放弃。
最终在Redis组件的高可用解决方案上,做出如下规划:把数据缓存功能通过Redis哨兵模式实现,分布式锁功能迁移至zookeeper作为分布式锁高可用解决方案。
为什么选择Redis哨兵模式?哨兵模式是主从模式的升级版,因为主从模式无法解决故障恢复问题,同时作为数据缓存组件,Redis中多为看板缓存数据,Redis哨兵模式与集群模式相比,资源占用更小,更贴近与Redis在TA中的实际定位。
zookeeper中的分布式锁主要是通过创建临时节点+心跳机制来实现的,我们的业务中有需要创建永久节点的场景,所以我们需要对这些特殊的锁进行封装,并在监控系统里建立删除过期节点的任务,以防止死锁。
// 3.4 监控运维高可用的实现
监控告警自动化运维系统是集群可靠性的关键保障,如果监控运维做不到高可用,那么当监控运维的主节点挂断的时候,我们收不到任何系统告警,也不可能进行自动化运维来修复组件的异常,等于整个集群在“裸跑”,整个集群处于“黑盒”状态,所以自动化运维的高可用极其重要。
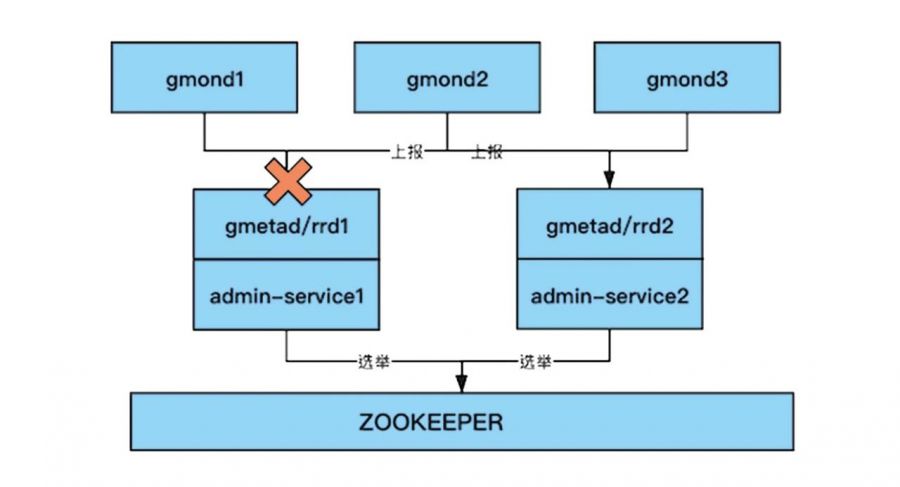
我们现阶段监控运维的架构是:由ganglia-gmond作为监控运维的agent,也就是监控数据收集及自动化运维下发节点,安装在每个TA系统的节点上,并用udp协议广播监控数据,ganglia-gmetad把收集到的监控数据写入rrd时序数据库中。
同时,我们自研了admin-service作为管理组件,将组件状态和告警动作存入MySQL表中,当组件的状态异常时,admin-service收到异常状态,并触发告警和自动化运维功能,尝试消除组件的异常。所以admin-service作为管理组件,也就是监控运维的主节点,是一定需要解决单点问题,做到高可用的。
我们仔细研究了监控运维的高可用方案。对于gmetad/rrd这套监控数据汇总和时序数据库组件,我们可以在两个监控运维主节点部署两套独立的gmetad/rrd,解决单点问题。而admin-service组件,对于自动化运维动作,我们已经做到了幂等,可以进行重复操作,但是告警动作,不能重复一次。所以,我们不能简单地部署两个admin-service来实现高可用。
我们需要引入zookeeper,并利用zookeeper的选主功能,来为admin-service选主。zookeeper的选主的原理是admin-service组件在zookeeper的一个目录下注册一个顺序的临时节点,并用心跳保持连接,并将注册值最小的那个节点,作为admin-service的主节点。当admin-service组件宕机下线,心跳丢失,临时节点消失。这样的好处是在有多个admin-service的情况下(TA系统一般为2个),避免“羊群效应”。该功能能使同一时间内,只让主节点的admin-service进行告警和自动化运维工作,从而解决告警的重复问题,保障监控运维的高可用。
// 3.5 流式处理引擎(数据ETL层)高可用的实现
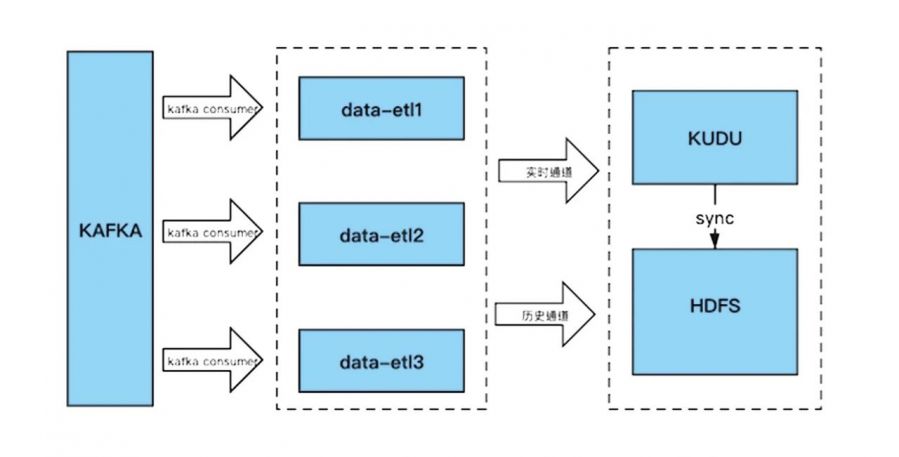
流式处理引擎底层是基于之前所述的开源组件Kafka-common做的数据ETL组件data-etl,其将数据从Kafka顺序存入Kudu和HDFS。
流式处理引擎data-etl实际上是我们TA系统最核心的部分之一,我们对数据ETL的处理主要可分为两种不同的通道:一种是吞吐量更大,但是有延时的历史通道;一种是吞吐量尚可,但无延时的实时通道。
我们主要介绍一下实时通道,它采取的是一种“读时合并”的技术,做到完全的无延迟。我们会在Presto中建一张跨Kudu和HDFS的视图,同时,历史数据会存在HDFS中,实时数据存在Kudu中,查询的时候通过视图,同时查询历史数据和实时数据,从而在查询端做到无延时。同时,我们会用“读时合并”技术,一点一点地把实时数据的历史分区搬迁到HDFS的临时目录中,搬迁完毕后,原子性地把临时目录移到历史分区,并删除Kudu历史分区。
流式处理引擎还有很多的功能,比如通过负载算法,在有负载空余的时候,将HDFS中的小碎文件进行合并等等。
对于data-etl的高可用,因为Kafka-common支持将offset存入MySQL/Redis表中,我们可以将多个data-etl,通过同一个consumer group.id来消费Kafka,Kafka会把partition均匀地分给多个data-etl。当有节点下线或上线时,Kafka会收到节点增加/减少信号,回收分区,并重新给data-etl分配partition。
Kafka因其架构原因,可能会有网络原因造成日志回退的问题,导致Kafka consumer消费Kafka越界。在出现这个问题的时候,Kafka给出了auto.offset.reset参数,并有三个选项:earliest、latest、none。earliest就是当消费越界的时候,从头开始消费;latest是当消费越界的时候,从尾巴开始消费;而none则是自己根据自定义的策略进行编码。我们选择了none,自定义策略,让Kafka在越上界的时候,从尾巴开始消费,越下界的时候,从头开始消费。
除此之外,我们还优化了Kafka Assignor分配策略,让Kafka在分配分区的时候,按照lag值(也就是当前的日志长度log size减去当前的消费长度offset)排序,然后尽量均匀地分配给不同的data-etl,来保证在分配partition的过程中,不出现数据倾斜。
同时我们也有一套数据倾斜监控算法,在出现数据倾斜的情况下,让data-etl重新平衡Kafka分区。
// 3.6 收数组件(数据收入层)的高可用的实现
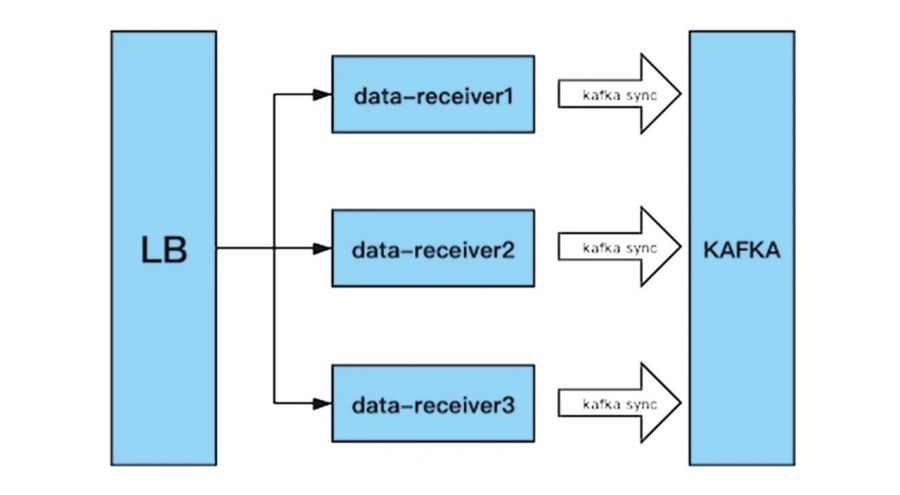
TA系统的数据接入层组件receiver,它的高可用也极为重要。因为如果receiver组件crash,数据将会丢失,影响收数的可靠性,我们receiver主要是提供http服务,并将数据通过http发送到Kafka缓存起来。
我们在TA集群中部署多个receiver节点,并在前端挂load balance,由load balance根据其具体的负载平衡算法,将数据转发至receiver节点,并提供故障监测切换功能。
至于具体的load balance,则需要根据客户的实际情况,要么使用lvs+nginx,要么使用云服务商的lb服务,要么使用F5等来保证高可用。
receiver节点发向Kafka,需要注意因Kafka异常导致的传输错误/堵塞,这时候,需要将receiver的数据保存到本地磁盘,并发送告警,在Kafka恢复正常后,再将这些数据发送给Kafka。
// 3.7 web/common-service组件的高可用的实现
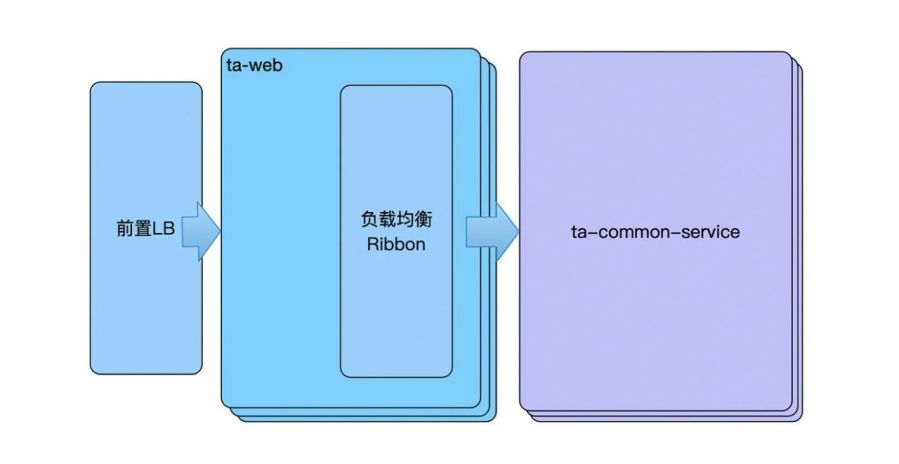
web组件承载了用户鉴权、数据业务请求转发等相关功能,它将鉴权通过的请求转发给下游的查询业务组件进行处理,高可用部署时只需要将本地缓存转化为分布式缓存,并配置前置LB。
web组件下游连接高可用部署的查询业务组件,因此web组件引入了负载均衡组件Ribbon。可以动态探测下游查询业务组件的存活,进行动态请求路由。
common-service组件为查询业务组件,与web组件类似,高可用部署后只需要将本地缓存转化为分布式缓存。另外针对需要并发同步的业务场景或定时任务场景,common-service组件引入了分布式锁进行业务同步。
综上,通过对不同层级的组件和模块设计实现不同的HA策略,从而达到整个TA系统的高可用状态,使得TA系统可以在日常运行的过程中抵抗不确定性风险,确保在任意组件或者某物理节点出现故障时,系统仍可以提供稳定高效的服务。
尤其是在游戏领域,数据量大,业务场景复杂,在面向全球发行业务时,由系统、网络、云服务等诸多不确定性因素叠加时,TA系统的全组件高可用方案为客户带来的价值更为突显。
来源:数数科技
原文:https://mp.weixin.qq.com/s/UM6PjFw-1KiHdRqcGdkTjw






 Steam
Steam  App Store
App Store 









 闽公网安备 35020302034348号
闽公网安备 35020302034348号