在17日晚的Unity线上技术大会中,掌趣科技技术专家林若峰针对Unity 2019新特性进行了分享。他所提到的技术点离手游行业更近,一系列实操的方法也充分考虑了项目落地的问题,因此对一些正在考虑品质提升的手游项目来说,或许有更多的参考价值。
本次视频也已经上传至Unity B站官方,视频中还有现场的精彩问答环节,大家也可以前往观看:
https://space.bilibili.com/386224375
以下内容为林若峰的分享:
大家好,我叫林若峰,目前任职于掌趣科技,担任技术专家的职位,主要在天马时空负责次世代手游《黑暗之潮》的客户端技术,以及公司的客户端框架的开发和维护。今天以《黑暗之潮》的开发经验为基础,聊一聊Unity2019的新特性,在实际商业项目中的应用以及落地的相关实操经验。
从Unity2018开始,Unity就引入了不少的新技术,不过一直以来相关技术分享仍以教程介绍为主,所以今天我们来看一下DOTS和URP这两项技术的实操,以及我们的一些心得和体验。
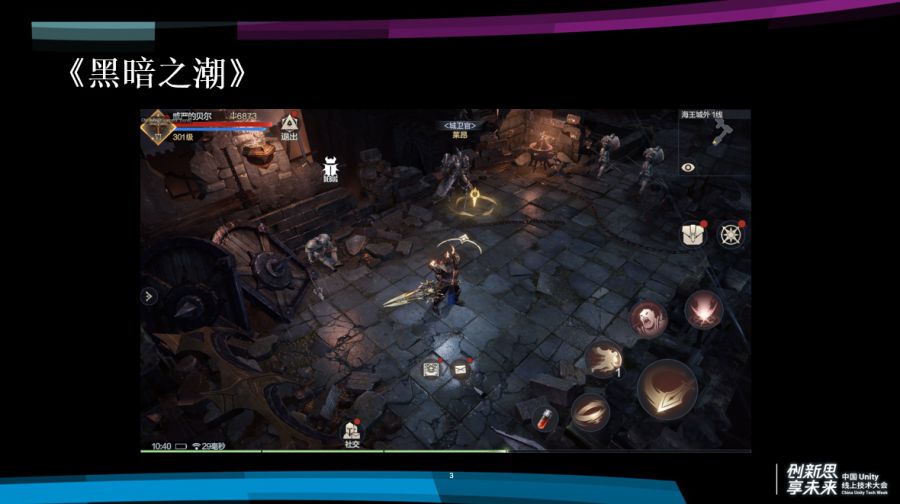
首先简单介绍一下《黑暗之潮》,这是一款顶视角的次世代手游,目前处于内测阶段,虽然它锁定了视角,但实际对画质和战斗细节的要求很高。大家可以从截图上看出,游戏采用了PBR的渲染,场景当中有不少的动态光影效果,场景的细节也相当丰富。
今天主要分享几块内容:首先是制作《黑暗之潮》这款项目的挑战,其次是我们在渲染管线的选择和定制方面的经验,包括当中可能遇到的问题,以及应用的地方;接下来我会就DOTS技术栈在我们项目当中的运用,聊一聊有关DOTS的常见误解;最后,我会分享一些项目工作流的简化和改善经验。
正题开始之前,先给ILRuntime打个小广告,ILRuntime是我制作的C#热更解决方案,目前已经在大量的商业项目当中得到了验证,比如掌趣旗下四款上线很长时间的游戏,都是采用ILRuntime进行的热更,大家如果对C#语言的热更方案感兴趣,可以在Github上进一步了解。
现在开始正题,先看当时《黑暗之潮》中遇到的挑战。
首先显而易见的,我们的游戏采用了PBR的次世代渲染技术,在画面表现上面有不少挑战。第二,我们希望适配尽可能广的机型,接触更多的玩家。第三,如下图,这款游戏的战斗强度非常高,会有大量的怪以及技能特效。
除此之外,这款游戏的战斗机制也有非常多特殊的定制,单一个职业来说,可能有上百个技能供玩家选择和搭配,在这些技能的实现过程中,对性能的要求会非常高。最后,由于采用了PBR的模型制作流程,在工作流方面也有繁多、复杂、出错的环节,需要针对这些环节进行简化。
下面第一个主题,是关于渲染管线的选择和定制。
《黑暗之潮》选用了URP技术,它是一个比较适合移动平台开发的PBR渲染管线,虽然说它是PBR渲染管线,但实际上非PBR的东西也可以用它来渲染。
我们当初非常看重的一点是,URP拥有非侵入式修改的能力,我们在不修改URP源码的情况下,可以对它进行比较多的定制。此外,URP有全部的C#源码,整个渲染过程基本全部能掌控在我们自己手里,当出现问题或者遇到bug的时候,比较容易定位。源码的结构清晰,组织也非常合理,所以我们扩展和自定义起来也会相对方便。
还有最关键的是,URP的性能比Builtin内置管线更好。可能有人会问,为什么我们要对渲染管线进行自定义,是不是因为URP有坑,或者不能实现什么效果,所以必须去自定义?实际上不是的,因为每个项目都有各自独特的需求,在更好地满足这些需求的情况下,就需要对渲染管线去进行定制。
举一个例子,这个角色释放了一个火焰效果的技能,但是这个火焰效果的特效被渲染在了地面的裂纹之上,这个其实是一个错误的表现。正确的表现是火焰的特效能够盖在这些地表裂痕的上方。
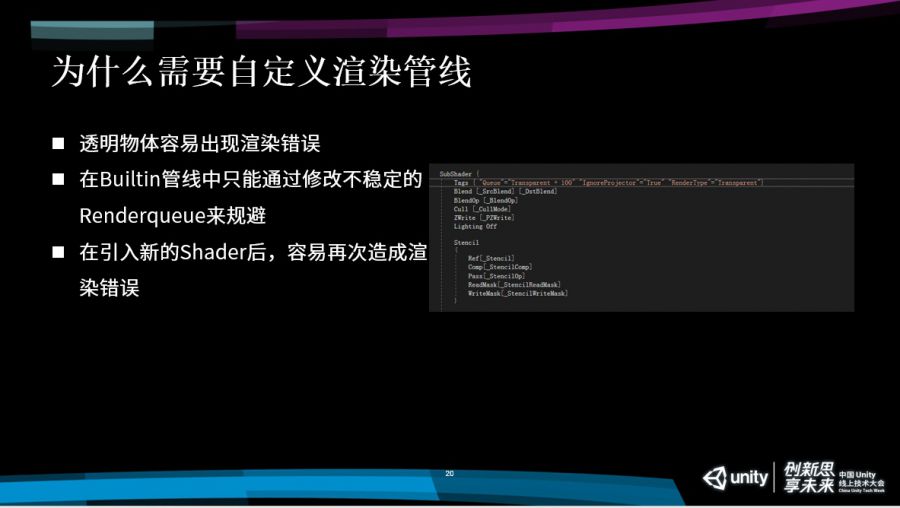
为了解决这个问题,以前我们在Builtin管线当中只能通过修改不稳定的Renderqueue,或者通过代码去修改这些物体的Renderqueue来规避问题。这么做有一个比较大的弊端,这时可能需要对这些物体新建一个Shader,或者要写比较复杂的逻辑来规避。
一旦引入了新的Shader,就有可能要重新去做一遍刚才做的这些效果,非常麻烦,而且容易反复出问题。在Builtin当中,一些效果其实只能通过Shader Pass去实现。比如要给这个物体增加一个描边,就需要在角色的Shader里额外增加一个Pass去实现。弊端是,在渲染过程中,势必会被多Pass给打断合批。
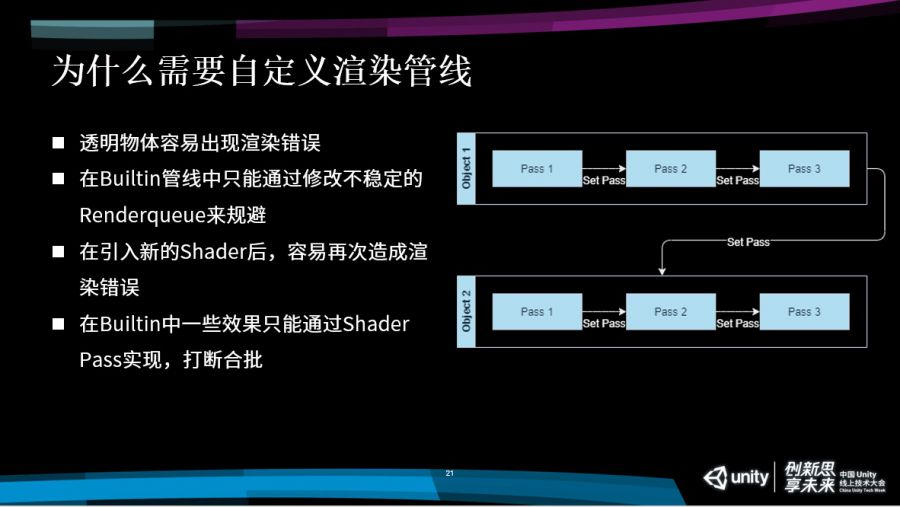
大家可以看到下面这幅图,我们如果在渲染object1的时候,如果它的Shader有多个Pass,我们需要首先渲染Pass1,然后通过一个Set Pass call渲染Pass2,然后再Set Pass call渲染Pass3,这个时候渲染完object1再渲染第二个物体时,又会把刚才的操作重新重复一遍,Pass1、Pass2、Pass3……渲染这两个物体的时候,就会有非常多的DrawCall,而且每次DrawCall切换开销都比较大。
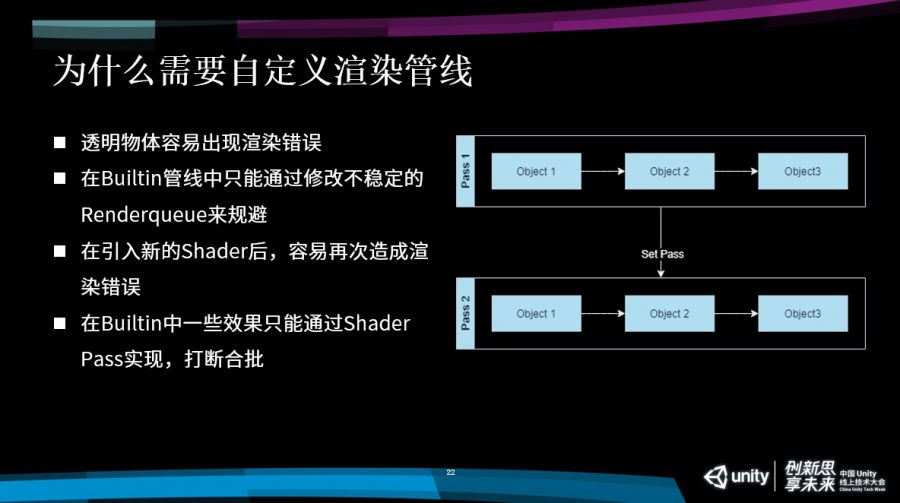
实际上有更好的方式,我们可以用这种流水线一样的方式渲染这两个Pass。我们在渲染Pass1的时候,我们会以一口气把所有的object1、2、3,一次性全都渲染了,渲染完毕之后通过一次Set Pass Call去渲染这个Pass2,实际上我们这三个物体总共需要两个Pass就可以渲染完毕,自然而然它的效率会高不少。
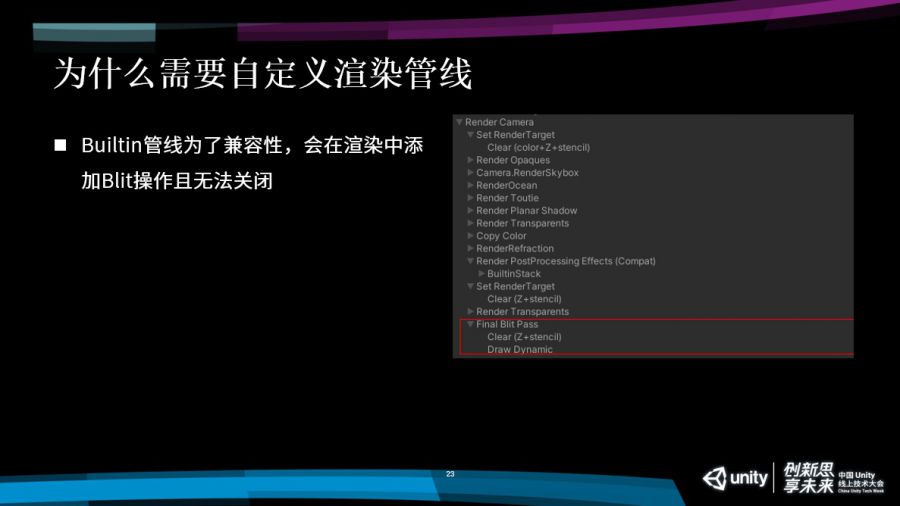
还有一个问题是,Unity是一个通用引擎,会考虑各种项目的情况,为了兼容性,它可能会在渲染的过程当中,在一些情况下加入Blit操作,相当于是把全屏的结果进行一次复制。
这个复制开销对于移动平台来说非常大,因为移动平台的带宽很有限。实际上,我们在自己的项目当中,因为对整个渲染流程比较清楚,知道哪些情况下可以使用Blit,或者不需要Blit,就可以看情况把它去掉。如果它能够去掉,对整个游戏性能会有比较大的改进,也能降低很多带宽开销。
另外,每个项目都会有一些特有的效果,比如下面截图里,对于URP本身,在默认情况下,像扭曲,空气扰动效果只对不透明物体生效,火焰效果在这里就会显得比较突兀,因为它不受扰动效果的影响。对美术而言,这样的效果就不是特别理想,所以我们可以对它进行定制,最后实现空气扰动同样能对火焰产生影响的效果。
接下来介绍一下URP在默认情况下的渲染管线的流程。
在开启了动态光影的情况下,URP它会首先去渲染主光源的Shadowmap,然后再去渲染附加光源的为Shadowmap,主光源在URP里面其实主要是指的充当太阳光的那么一栈方向光,附加光源除了那栈方向光以外的,比如点光源,射灯之类的动态光源,在渲染完这两张shadowmap之后,URP会进行一个叫做Depth Prepass的操作。
稍微岔开一些话题,Depth Prepass这个名字可能会有一些误导。通常来说,Depth Prepass的最主要的作用就是预先把整个场景所有物体的深度渲染一次,后面再进行不透明物体渲染的时候直接使用深度的结果进行深度测试,从而尽可能去利用Early Z把一些不必要的片源去掉。在AlphaTest的时候,像素的深度实际上要在比较后期才能够决定的,如果没有Depth Prepass的话,有可能Early Z会在这些地方失效。
但在URP当中,Depth Prepass并没有上述这个作用,实际上只是把场景里面所有的物体深度渲染到一张单独的RT当中,给后面的效果进行使用。
回到管线流程,做完Depth Prepass之后,会进行所有不透明物体的绘制,绘制完毕之后会进行天空盒的绘制,绘制完天空盒之后,会进行Copy Color的操作,如果用户在渲染管线的设置当中,开启了Color Pictures这个功能,它就会进行这个操作,把当前的渲染结果复制到一张独立的RT上面,供后期的效果使用。
接下来会进行所有透明物体的绘制,绘制完透明物体,会对全屏进行后效处理。如果大家还有UI,会在这个时候去绘制,绘制完UI之后,会把当前所有的渲染结果进行最后的一次Blit操作,把它给复制到屏幕缓冲区当中。
那么我们怎么去对URP内置进行定制?
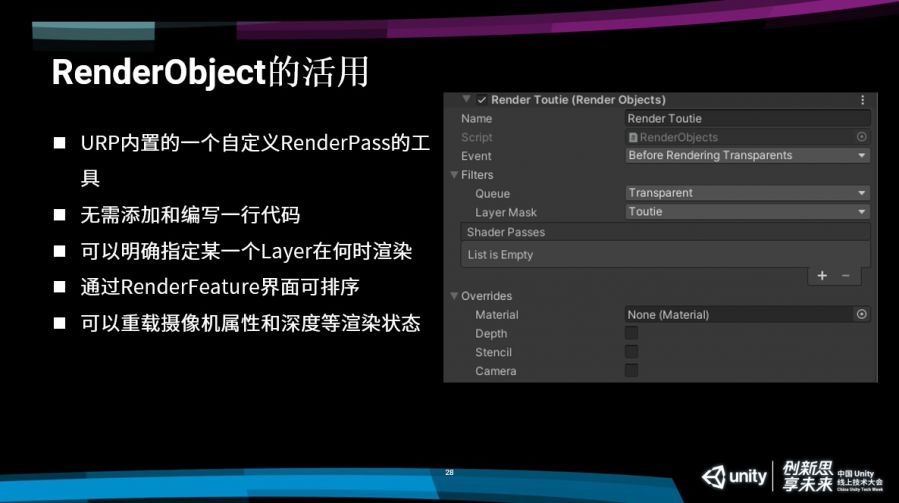
第一,URP默认的情况下提供了一个比较简单的东西,叫做RenderObject,它是URP已经实现好的RenderFeature和RenderPass,关于RenderFeature我后面详细再说。通过它,我们可以在不写一行代码的情况下,对渲染管线进行定制。我们可以明确设定一个layer,以及这个layer需要在哪一个具体的时间点进行渲染。此外,我们还可以在选择透明物体渲染之前,去做RenderFeature,并且做一些额外的设置。比如绘制涂层的时候,选择需要使用哪个彩色球,也可以选择不进行重载等。
我们还可以对一些渲染状态进行重载 ,对深度进行重载,来决定这个东西是否写深度或者做深度测试,以及对模板缓存的方式进行具体设置。对于摄像机的参数,我们可以去设置,包括单独对某一层的物体使用不一样的FOV,这在FPS类游戏应用比较。甚至我们可以对camera变换矩阵进行重载,拍一个跟主相机完全不一样的区域,这也是可以实现的。
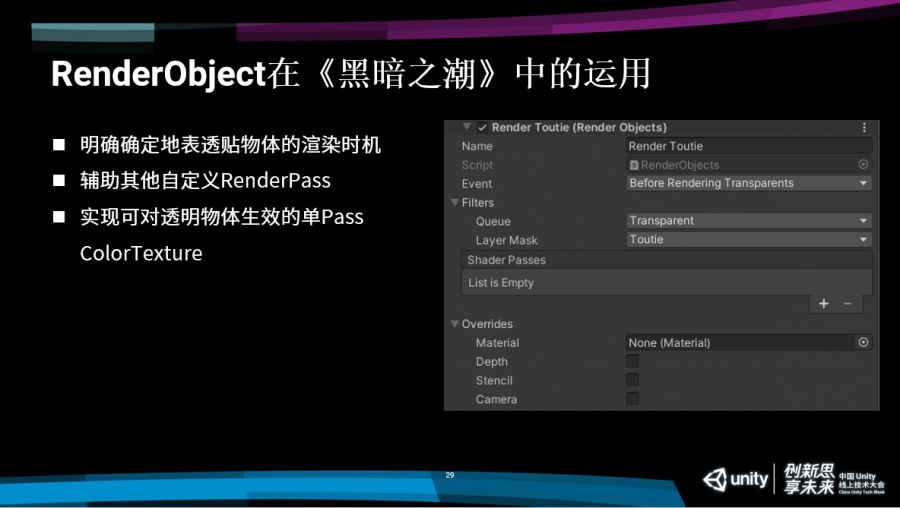
在《黑暗之潮》中,我们利用RenderObject主要是进行了这些的操作。
第一,解决我们最开始提到的例子,地面的裂纹这些透明物体的渲染,解决它的渲染不确定性。我们单独使用了一个RenderObject,选中了刚才地表的那一层layer,让它在透明物体之前去渲染这一整层,就能保证会在所有技能特效之前去渲染地面的裂纹,这样就不会出现刚才例子里面提到的错误情况。
第二,RenderObject也可以辅助其他的自定义RenderPass,我们在后面讲RenderFeature和RenderPass的时候会具体说这样的用法。
第三,刚才提到我们想要对透明物体也能够实现扭曲的效果,需要把复制那张ColorTexture的时机往后挪,挪到透明物体之后,用单独的Pass额外的去渲染这些需要扭曲的效果的特效,才能完成正确的渲染。这就是通过RenderObject去实现的。
接下来介绍一下RenderFeature和RenderPass的自定义。
这是URP提供的比RenderObject更高一层级的自定义,通过RenderFeature基本上可以做到在任意一个时间点插入自己想要的渲染操作,我们就会拥有更强的控制能力。因为在RenderFeature里面可以通过手动调用CommandBuffer底层渲染接口,这能实现非常多的效果。
此外,在使用RenderPass的时候,可以在切换RT的时候,通过RenderBuffer的LoadStore操作来进行性能优化。我需要提一下,在切换RT时的RenderBuffer的LoadStore操作具体是什么含义?
现在移动GPU基本上都采用了tile base的架构,渲染的时候GPU会有一个叫片上内存的东西,它所有的渲染结果实际上是直接对片上内存进行操作,而不是直接对显存进行操作,就能够减少频繁读显存所带来的带宽开销。
我们在渲染的时候需要提前告诉GPU,现在切换了一个RT,告诉GPU我们是否需要把RT本来保存的颜色系统首先加载到片上内存,然后再进行接下来的渲染操作。
实际上在很多时候,我们能知道这个操作是不必要的,每次渲染新的一帧时,肯定要对屏幕上所有的像素进行重绘,或者类似做后效的时候,肯定需要对所有的像素进行重新绘制,RT之前本来保存什么样的信息,完全就没有任何意义。
这时候我们可以告诉GPU,你不需要帮我们把RT上面的内存加载到片上内存,自然而然这个加载就不需要有任何的带宽开销,我们就可以省掉一大部分的带宽开销。
同样,对于写操作也是一样,如果说一个深度图,这个深度只是拿来做深度测试,深度的结果不需要写回RT里面,那我们就可以在切换RT的时候告诉GPU,渲染结果不需要写回RT内容。
接下来介绍一下我们《黑暗之潮》项目当中利用RenderFeature做了什么效果?
第一,平面阴影,这是一种作假的阴影渲染方式,它只适用于游戏大部分都是平地的情况,正好《黑暗之潮》就是这样一款游戏。
平面阴影有一个优点,大家可以看到下面的截图,阴影是非常锐利、非常清晰的,它的整个的渲染质量很高,不会出现任何的锯齿。还有一个比较大的好处是,因为它不需要去额外渲染shadowmap,在渲染地表的时候也不会需要对shadowmap进行采样,这样的话,这个渲染的整体开销要比使用shadowmap省非常非常多的。
这个效果用RenderFeature就可以非常容易的实现,我们直接添加一个Shadow RenderFeature,把需要有阴影的角色用一个特殊的shadow绘制一遍就可以了。
第二,我们用RenderFeature实现了沙盘地图地块描边的效果,大家可以看到这个截图,描边需要严丝合缝地对应这个区块范围。同时,区块下半部分,墙、山体不能有描边。所以我们在做这个效果的时候,没有办法运用到传统的描边方式,即利用法线往外扩的方式去渲染这个描边。
我们采用的流程是这样的。首先我们用一个纯色去渲染这个地块,渲染出来了之后我们对这个渲染结果进行降采样,缩分辨率,在比较低分辨率的情况下,再利用BoxFilter进行模糊操作,这样做的好处是,可以利用尽可能小的带宽开销来对这个结果进行模糊操作。
然后再将模糊完毕的结果进行升采样提高分辨率,最后再用透明的颜色绘制一次地块,就把中间这个区域扣除了,只剩下外面的描边,这样就可以实现刚才描边的效果,并且还能实现从描边从靠近物体的部分往外慢慢渐变渐影的柔和的过渡效果。
接下来还有更深一层次的自定义,有一些效果或者需求我们必须需要更深层次的自定义才能够实现的。在URP当中,提供了一个叫做Renderre的机制,它是一个抽象层,URP里面内置了两个渲染器,一个是Forward,也就是我们常说前向渲染器,另外一个就是2DRenderer,主要是用来渲染2D物体的,一些2D游戏可能会选择这个渲染器。
在最新版的URP当中,还会集成了一个叫做defer Renderer延迟渲染器,在《黑暗之潮》当中我们可以对Renderer进行寄存,通过它去实现一些通过RenderFeature做不到的事情。
URP有一个好处,虽然说我们想要自定义Renderer,但并不意味着我们所有东西必须要从头开始做,因为URP里面已经实现了各种各样的Pass,我们是可以直接使用的,所以我们只需要对这些Pass进行重新编排就能完成我们对这个Renderer的自定义。
《黑暗之潮》当中对ForwardRenderer基础上面进行了一些修改做到了自定义。能做到,比如之前提到的全屏Blit操作,是否把它给避免掉。
我们观察到,比如做后效时,这个后效不可避免对全屏所有的像素进行操作,正常情况下,如果说我们后面还需要渲染UI,会在这个后效计算完毕之后渲染UI,最后通过Frame Blit去复制到FramBuffer里面。
所以我们就在想,这两个过程能否合并,答案肯定是可以的,在做后效的时候,在计算完毕后直接将结果写入FrameBuffer里,实际上我们就能够省掉Final Blit。最后在渲染UI的时候,我们就把这个UI直接在FrameBuffer上面去进行绘制。这个样子就可以省掉最后这个Blit的操作。
这么做还有一个好处,我们可以把3D场景的渲染分辨率和UI的渲染分辨率分开。以前如果我们因为受制高低配 ,对整个渲染结果的分辨率进行降分辨率操作,那么UI也会跟着一起被降分辨率,但是UI对分辨率很敏感,只要一降分辨率就能够肉眼可见,而且对整个游戏的品质影响很大。
所以如果我们能够把3D场景的渲染分辨率和UI分辨率分开,就能在降低渲染开销的情况下又不对整个游戏的品质产生比较大的影响。经过刚才的介绍方式,就能够实现这两个分辨率的分开,因为我们3D场景在RT上面渲染,渲染完毕之后,通过后效复制到FrameBuffer上面,UI是直接在FrameBuffer上面绘制的,所以说UI的分辨率是不受降分辨率的影响的。
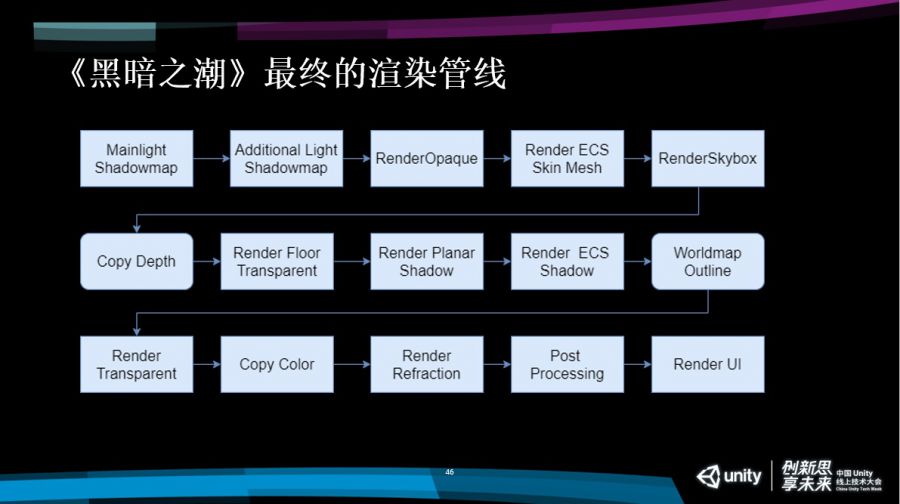
总结一下,《黑暗之潮》最终渲染管线由流程图展示如下,前半部分跟默认的URP没有太大的区别,主要是在渲染不透明物体之后,我们加入ECS模型渲染。我们这个地方还有一个Copy Depth ,把不透明物体的深度给复制到一张单独的RT上面。
这个Pass不是每次渲染都会有,而是只有开启沙盘地图的时候才会用,因为沙盘地图在渲染水体的时候会需要那张深度图。接下来我们就会去渲染地表的这些不透明物体,渲染所有的平面阴影以及ECS物体的平面阴影,绘制沙盘地图的描边。
最后再去渲染我们的透明物体,也就是特效这些东西,渲染完特效我们会在进行这个copy color,把整个渲染结果复制到一张单独的RT上面,而且这个RT是进行了降分辨率操作,实际上抓取的并不是全屏,大概只有1/4屏幕的分辨率的颜色信息。
这个颜色信息给类似于扭曲这些效果去使用,因为这些效果对分辨率的要求并不是特别高,因为本身已经扭曲了,之前采用1/4分辨率的贴图是没有任何问题的。渲染完扭曲之后,我们会对整个屏幕进行后效处理,后效处理完毕之后,结果可以直接写在FrameBuffer屏幕缓冲区里面,最后再去对UI直接进行绘制,完成了整个渲染流程。
说完URP的功能,下面说一下关于URP性能方面的优势。
首先第一点,URP的特点它是一个单Pass的前向渲染管线,单Pass也就是说所有的动态光照是在一个Pass里面完成计算的。单Pass最好的好处是,我们在添加动态光源的时候,不需要把场景里面所有的物体再去渲染一遍。以前在内置管线的时候,这个问题会比较严重的,如果我们添加一盏动态的点光,场景的DrawCall直接翻倍了,这个渲染开销根本没有办法忍受,所以之前在移动游戏基本上不会使用动态的点光源。
大家可以看到下面的截图,我们这个场景实际上已经有好几盏动态光源了,通过单Pass的方式渲染的话,只要我们同场景里面同时能看见的这些光源的数量能够有一个比较好的控制,实际上是能够实现很好的一个渲染效果的,而且这个渲染开销相对来说也比之前多Pass光照渲染就会是有非常大的优势的。经过我们测试,在目前主流的终端机以上,中高端机都是没有任何问题的。
第二点,URP它采用了单Pass的Color Texture去替代GrabPass,之前我们在Builtin管线里面做类似于空气扰动之类的效果,必须要使用GrabPass无这个功能的。这个功能虽然非常方便也比较简单,但是它有一个非常严重的问题,我们使用GrabPass之后,我们完全没有办法预知当前渲染屏幕会被全屏抓屏几次,而且这个抓取是不会降分辨率的,真的就是全屏抓取,全屏抓取操作是非常非常废资源的,尤其是在移动平台上面,基本不大能忍受。
通过这个单Pass的ColorTexture就可以通过一次抓取来完成所有需要扭曲操作的渲染,这个无疑性能就会高的非常多。也就是刚才介绍到的通过RT可以去自定义LoadStore这些操作,也能进一步减少带宽。刚才也说了,我们可以根据实际情况去掉一些不必要的Blit操作。
最后还有一点非常重要,SRP Batcher,单这一条就已经不能拒绝URP的使用。
我们看一下SRP Batcher对项目有什么具体的影响?
首先在内置管线当中有三种方式去进行合批,第一是Dynamic Batching,它实际上对合批有比较严格的要求,对于三角面数要求比较高的。它还有一个问题,它是通过CPU降低DrawCall我们降低DrawCall的目的也是为了降低CPU开销,相互意义已消,只有在一些特定的情况下,Dynamic Batching才能够有性能提升,绝大多数情况下是没有太大作用的。
第二,静态合批Static Batching,这个东西确实是非常有效,对降低DrawCall和提升性能都很有效,但是它最大的问题是它只对静态物体生效。对于动态物体完全没有任何效果的,而且进行静态合批之后,整个场景的内存占用会提高非常多。还有一点,随着现在场景复杂度的提升,现在次世代的游戏都已经场景都已经非常复杂了,LOD就是一个非常不可或缺的功能了。Static Batching对LOD是非常不友好的。
最后还有一种方式就是GPU Instancing,这种方式只对网格Mesh以及Materia均一致的情况下才能生效,这个应用的范围比较窄了,一大片的草,一片大的石头,对于普通的物件,比如房子,场景物件,没有办法对它进行合批。
综上所述,上面三种合批方式如果用于次世代游戏是有些捉襟见肘,很多都没有办法合批,就会造成对于做这样的游戏,性能方面的优化就会非常的困难。
而SRP Batcher就能很好的解决这个问题,因为我们观察之后能得出一个结论,实际上DrawCall里面,开销最大的就是SetPassCall,SRP Batcher它的原理就是通过降低SetPassCall的数量来去打造性能提升,它降低的并不是DrawCall的数量。
通过把所有的渲染当中所需要用到的参数变量拆分成几个若干个Constant为Buffer分别保存,比如保存的是全局的静态参数,有一些可能保存的是当前这一帧数据,剩下的一个Buffer保存的是当前这个材质球特有的参数,这样做好处比较明显了。
如果说我们同一个Shader物体,它实际上变化的就只有它的模型以及材质球上的参数。至于像它的Shader的program,以及它的渲染状态,这些都是不需要改变的。所以说我们一次DrawCall基本只需要传一些参数,ConstantBuffer的内容,再去绑定一个Mesh的指针就可以完成了,这样整个DrawCall的开销就会非常低。
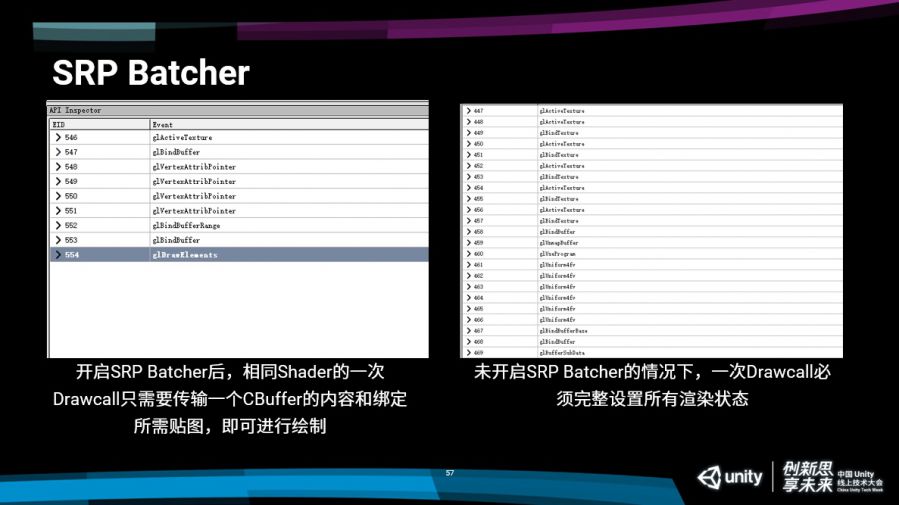
大家可以看这两张图的对比,左边是开起来SRP Batcher,右边没有开启,这个图是通过RenderDoc抓取的一次DrawCall的渲染流程,左边大家可以看到绑定了一个贴图,传了一些顶点的指针,最后通过一个BannerBuffer把ConstantBuffer数据更新一下,最后可以直接去绘制了。
但是在不开启SRP Batcher的情况下,大家可以看到整个渲染流程非常的长,会进行非常多的设置,还会去更改Shader program,还要更改非常多的渲染状态,这个截图还不全,这个列表下面还有很长一段,大家通过对比直接列表的长度就能说明这两个DrawCall之间的性能开销差别有多大。
对此我们也进行了一个测试,我们拿了一个测试场景,这个场景有三栈动态光源,这个场景在顶配的情况下,大概有40W三角面,以及500dc;中配进行简化过有32W三角面和400dc,低配是25W三角面和280dc。三档机型上面实际测试都有比较大幅度的提升,这个地方我想拿低端机举个例子,低配大家可以看到25W三角面和280DrawCall,实际上之前在Builtin的项目里面已经是一个高配才能比较流畅运行的标准了。
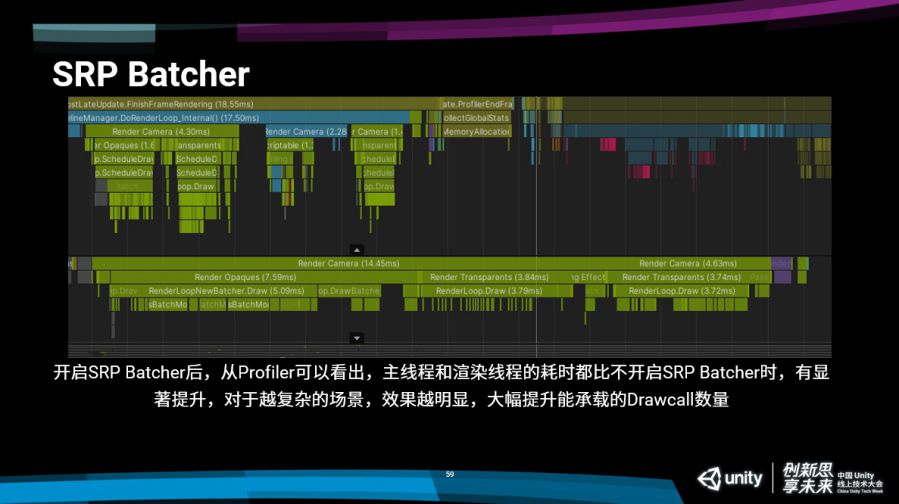
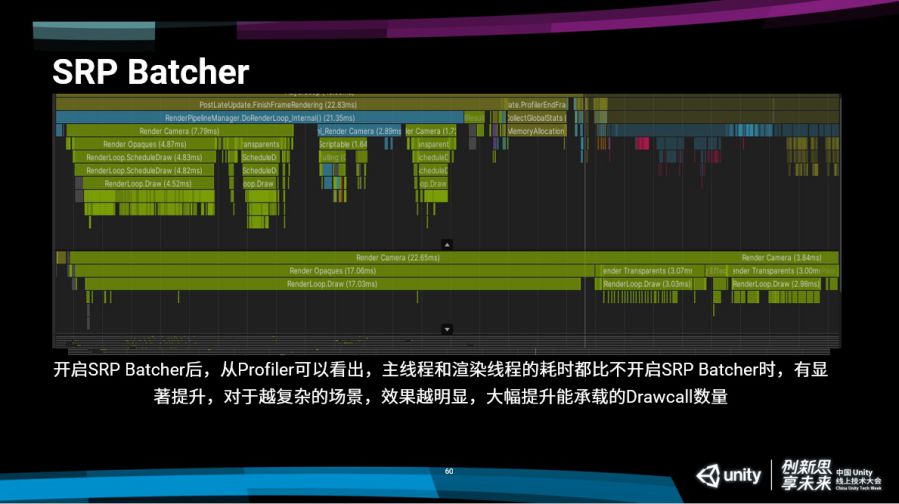
大家可以看一下这个Profiler的结果,我们是在一个骁龙450SoC上进行的测试,这是一个非常低端的处理器。大家可以看到我们的主线程Render Camera是4.3毫秒,在下面渲染线程Camera的开销是14毫秒。
我们再把SRP Batcher关了之后再看一下,相同的场景一模一样的东西同样的视角,主线程的Render Camera的开销已经直接涨到7.8毫秒,渲染线程实际提交的过程中我们整个渲染开销就已经达到了22毫秒。22毫秒已经相当于说,我们场景里面,只有场景,没有任何的技能特效,没有其他的角色,也没有任何的业务逻辑,就已经不大能跑30帧了,这个渲染就不大能够接受了。
讲完了刚才关于URP的东西,功能性以及性能上面的优势,接下来我想跟大家分享一些关于DOTS技术栈在商业上的运用。
我跟其他开发者进行交流的时候,会发现有一个问题,大多数的开发者都会有一些常见的误解,对于DOTS技术栈,第一个非常典型的,会听到非常多的人说,我们在项目里面没有用到多线程,所以也不需要用DOTS。
还有一个,可能大家会觉得用DOTS必须要用于大规模的集群模拟才能带动比较大的提升,因为之前大多数的分享,都是去演示的大规模集群模拟的性能的提升,可能会给大家带来这样的一个错觉。
大家会觉得使用ECS的代价会非常高,因为首先ECS是一个全新的东西需要重新学习,把现在的项目转换成ECS,代价也非常的高。可能也就用不上DOTS,这三个都是多多少少是一些误解,我在后面会给大家介绍,DOTS应该怎么样使用。
首先我们需要了解一下DOTS具体是什么?它实际上叫Data-Oriented Tech Stack,它的意思实际上就是面向数据的开发栈。它主要是由三个组建组成的,ECS、JobSystem、Burst。这三个组建是可以相互独立使用,并不是说使用一个这三个必须同时用,你可以任意选择其中一个来进行使用,用于不同的应用场景。
如果说我们需要使用JobSystem,其实它跟ECS没有太大的关系,你可以在ECS里面用,也可以不在ECS里面用,只要是需要并行计算的地方都可以使用。
Burst也一样,它也不需要配合ECS使用,不需要跟并行计算捆绑使用,它的作用仅仅是对于一些复杂的计算密集的东西去进行编译器优化,来达到性能提升。
只要是计算密集型的东西,都可以使用Burst,同步方法也是可以的。
最后关于ECS,一个比较大的误解,可能大家会觉得用ECS之后,所有东西都可以用ECS来写,就会想UI的业务逻辑怎么用ECS实现。大可不必,并不是说用ECS,所有东西全部都要用ECS来做,而是大家可以根据项目需求选择其中适合那部分来用ECS去写,剩下的部分还是使用传统的面向对象的方式去写,没有任何问题,只要用代码稍微结合一下就可以了。
第一个我想给大家看一下,我们在《黑暗之潮》当中利用ECS的例子,我们通过ECS渲染了大量的怪物。我们游戏里面怪物通常有一个特点,一组怪由几名精英配合一两种大量的存在的爪牙组成的,大家可以看到右面的图只有三种怪,如果说用默认的SkinMeshRenderer的话,就有一个非常严重的问题,没有办法合批了,画面上面有多少个怪,有多少个DrawCall而且Animator开销也不小,还有一个问题,GameObject为.Instantiate开销也是比较大的,如果说我要同时刷出来三四十只怪的话,肯定会卡顿,用ECS就能比较好的解决这三个问题。
使用ECS先把整个动画信息去烘焙到这么一张动画贴图上面,在GPU当中进行蒙皮操作,我们再通过JobSystem和Burst实现视锥剔除和动画系统的更新,最后我们再在面向对象那块业务逻辑那块控制ECS Enity就可以了。也就是说ECS的部分,我们只是提供渲染的和动作的结构,其他部分业务逻辑还是完全用面向对象去实现的,相当于各取所长。
用ECS最大的好处就是性能。
首先第一个,因为我们采用了GPU蒙皮,整个DrawCall的数量下降到有几种怪就是几个DrawCall,这个就非常好了。实例化也是非常快,ECS基本上就是无感的,在极端机上消耗,即便同时刷一千只怪也不足1毫秒,借助Burst力量类似于视锥剔除这些计算量比较大的操作,在低端机上也是可以忽略不计的。
大家可以看到下面的截图,演示我们整个动画更新阶段,也是同样在骁龙450 SoC上测的,100只怪左右的情况,动画整个更新过程只用了0.008毫秒,这就是忽略不计,根本不需要考虑的一个量级。通过ECS,我们画面上怪物的渲染完全取决于GPU本身的渲染性能,CPU的开销完全不需要去考虑了,所以也不会出现卡顿。
第二个,我们通过Jobsystem去实现了怪物击飞的效果,大家可以看到这个怪物被打下悬崖,它如果说碰到墙壁必须要被墙壁挡下来,需要进行一些物理运算,如果直接使用Unity的Ragdoll也就是布娃娃系统,它的物理计算非常复杂,对于低端机会造成比较大的性能负担。我们把这个过程稍微简化了一下,所有的这些怪物在被击飞的时候,使用的是预先制作好的动画,我们只需要计算它的运行轨迹就行了。
我们首先用Job去并行计算这些怪物的分析轨迹,再通过Unity提供的多线程Raycast方法去进行射线检测来判断它是否撞到墙或者碰到地面了。最后如果说我们还有一些非ECS了对象,我们可以在计算完毕之后再通过一个单独的Job把这个所有GameObject的位置给同步一下就可以了。
第三个,我们通过Burst实现的就是射线技能,这个东西看上去很简单,实际上需要对整个场景以及所有的怪物和其他对象产生交互。射线打到墙上能够实时产生反映,我们这个东西需要每帧对整个场景进行射线检测,整个计算过程实际上是开销比较大的。通过Burst我们相当于把这个东西做成了一个Job,通过Job.Run的方法去直接进行调用,就是在当前这个线程进行的操作。
使用起来跟一个静态方法没有太大的差别,还有像大家看到的这个技能,会有大量的子弹,对这些子弹我们同样需要进行运行轨迹的计算。通过Burst非常有效的把这两个计算开销降的非常低,Burst开启之后,它的性能提升基本能上百倍,通过刚才也提到Job.Run的方式实现同步调用,我们在整个计算流程当中不需要开额外的线程,直接在当前线程,单个静态方法直接调用就可以了,也是非常方便的。
大家可以看一下开启和不开启Burst效果的差别,左边是开启,右边是不开启,我们在一个计算体系化模型工具中测试,左边只用241毫秒,右边用了20毫,真是一百倍的差别。而不是说它用了多线程所以更快,大家可以看到每个线程都快了100倍,如果算总耗时,这边用了143秒,这边只用了1秒钟,如果把所有线程的时间加起来,就是100倍的差别,效果非常明显。
最后跟大家介绍一下我们在工作流方面的简化和改善。
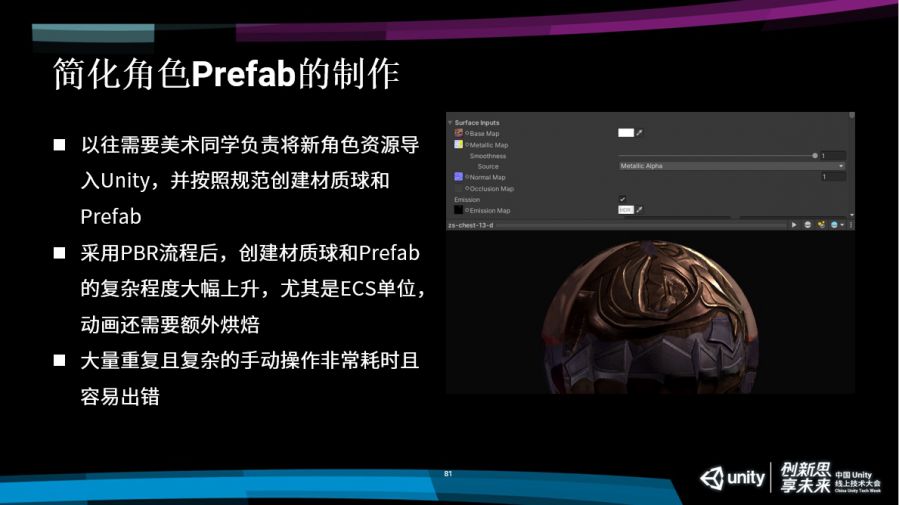
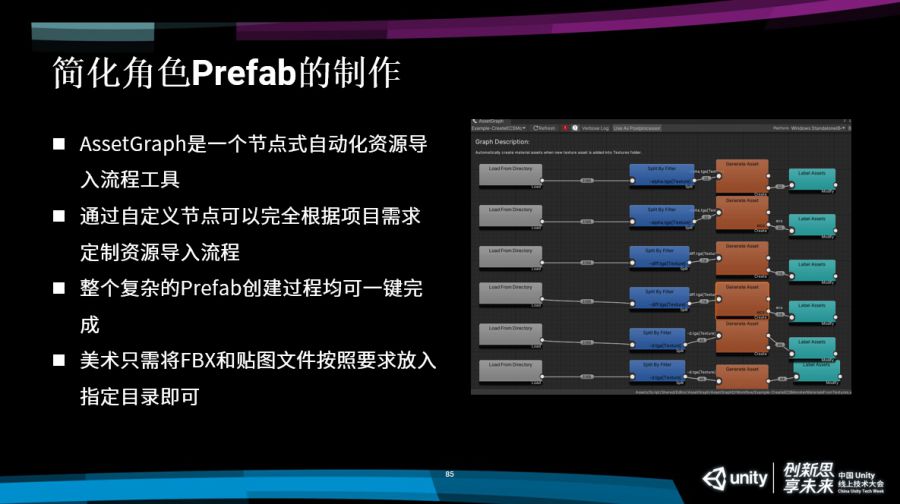
这部分由于时间的关系可能就只能讲的比较粗略了,大家稍微理解一下。首先随着我们采用PBR流程,Prefab的制作就会比较麻烦,而且以往这个Prefab的制作都是交给美术同学,美术需要把模型导入Unity,再规范创建材质和Prefab。
在采用PBR流程之后,这个创建过程就会麻烦了非常多,首先贴图多了很多张,跟各式各样的PBR的设置,是非常繁杂的。尤其是ECS的单位,我们还需要对这个动画进行烘焙。这是一个非常复杂而且操作量非常大的操作,非常的耗时,而且容易出错。
为了解决这个问题,我们引入了AssetGraph这个工具,这个工具是Unity开发的一个节点式的自动化资源导入流程的工具,非常好用。通过自定义节点,我们可以完全根据项目的需求对资源的导入进行自定义,通过这个工具,这个节点自定义完成之后,我们就可以实现一键就能够创建所有的角色的Prefab,所以说美术也就能从工作当中解放出来了,美术也只需要做完了之后把FBX和贴图文件按照我们定好的规定就放到指定的目录下就可以,它连Unity我不需要开,美术非常喜欢这个功能。
我们通过这个工具对这些模型进行批量的一次性Prefab生成,能够直接稳定的生成一个符合规范的Prefab文件了。这个过程当中大家肯定也知道我们如果用Animator都需要建立动作状态机这个东西,这个东西手动建立非常麻烦,所以我们也可以用刚才那个工具就能够实现在美术把这些动作文件、模型文件上传之后可以一键把整套东西自动生成了。
我们在导出场景的时候有些时候需要对渲染物件进行渲染设置,来达到最佳的渲染性能,具体的设置方式实际上是技术团队根据Profiling的结果进行不断的迭代和调整才能形成一个调整的方案。每一次调整,都需要去修改美术资源,如果说这个都需要美术去进行操作,整个工作量会非常的大。这是美术那边没办法接受的,所以说我们需要把这个过程稍微自动化一下。
为了提升切换场景的加载速度,我们需要对场景进行切块和分簇,大家可以从下面的截图看到,这些蓝绿色的这些盒子就是我们分簇切块之后的结果,它所展示的分块Bounding Volume。
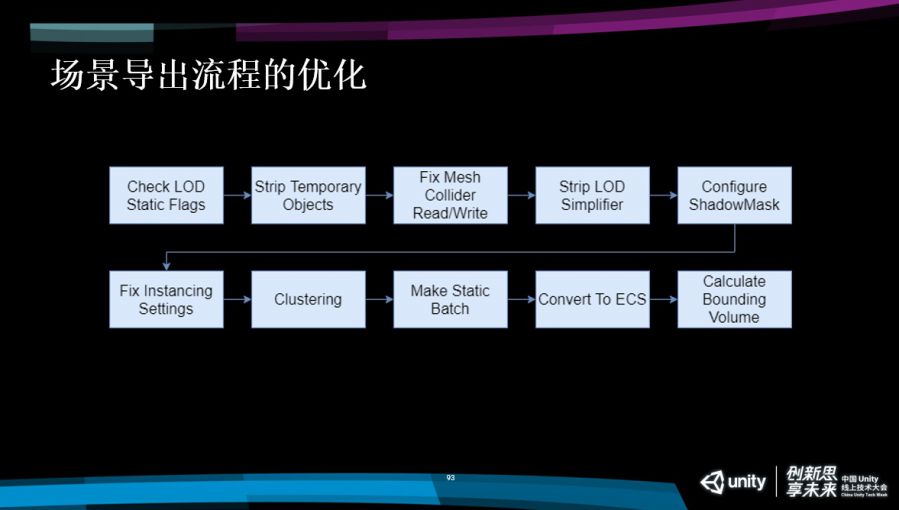
结合刚才所讲的我们整个场景的导出流程就会按照这个流程图的方式进行一步一步做。
第一步,我们会检查美术设置的LOD的选项是否正确,会把美术那些临时物件给剔除,有一些碰撞Fix Mesh Collider ReadWrite这些设置是否正确,还会把LOD的点面工具的临时脚本给删掉,最后还会对ShadowMask去进行一些设置,因为URP里面没有shadowMask,这是我们自己实现的,所以会需要一些额外的设置。然后会根据我们Prefab的结果去进行一些详细的设置,比如Instancing的设置该怎么设?哪些物体适合Instancing,那些适合,我们都会去进行设置。我们会对整个场景进行分簇会看哪些物体适合进行Static Batch,Static Batch不是所有物体都会适合,我们会进行一些选择。
剩下一些物体适合转换成ECS hybrid方式渲染,我们会转换成hybrid,最后我们再把每一个簇进行Bounding Volume的计算就完成整个场景流程的导出。我们在场景导出完毕之后,整个场景就是这样一个空场景的状态, 里面只剩下错的节点,就会对进入这个范围之后再进行动态的加载,这就是我们生成的每一簇的Prefab以及静态合并的Mesh。
以上就是本次分享的全部内容,谢谢大家!






 Steam
Steam  App Store
App Store 




































 闽公网安备 35020302034348号
闽公网安备 35020302034348号