5月10日至5月12日,Unity全球开发者大会Unite Shanghai 2019在上海召开,期间诸多技术专家来到现场为开发者分享主题多元的技术演讲以及行业趋势分析。
腾讯云互联网行业架构师余多,在大会期间进行了“游戏架构和云服务的耦合前瞻——匹配对战和连续大世界”主题演讲,分享了云计算将对游戏带来哪些改变,通过对匹配对战类游戏解决方案和连续大世界类游戏架构的剖析,展望云计算时代游戏的未来。
以下为演讲内容整理:
大家好,今天来这里和大家一起做一个前瞻性的探讨,关于游戏架构和云服务的耦合。今天的主要内容会由两个游戏架构组成,一个是匹配对战类游戏架构,这个我会讲的简单一点。另外一个是连续大世界的游戏解决方案,这个方案我们会一步一步的拆分出来。
首先,我们快速回顾一遍游戏和科技发展的关系。我个人接触游戏是从街机、家用游戏机开始,那时候大家都在自己的电脑上、街机房里用手柄玩游戏。随着科技的发展,个人电脑走进了生活,鼠标带来了操作方式的转变,RTS游戏开始崛起,鼠标帮助RTS游戏进入了大家的生活。接着,互联网进入了我们的生活,网络游戏出现,大家玩游戏的方式也发生了变化,从之前在家里自己玩游戏或者和小伙伴玩游戏,变成了在互联网上和陌生人、新朋友一起玩游戏。
再往后,智能手机的普及和4G网络的开启,带来了手机游戏的黄金时代。很多休闲游戏APP出现在我们的手机上,并且渐渐变得越来越复杂,游戏性也越来越好。随后,AR、VR和LBS技术方案的成熟,给我们带来更新的游戏体验。
我们可以看到,随着科技的发展,游戏的创造力会不断释放出来,游戏的体验和形式也不断发生翻天覆地的变化。那么,当云计算时代到来,云计算能够为游戏带来怎样的变化,能够为游戏体验带来怎样的提升?这是我们今天初步探讨的一个点。
我们就两个游戏架构进行探讨,首先是匹配对战的游戏。
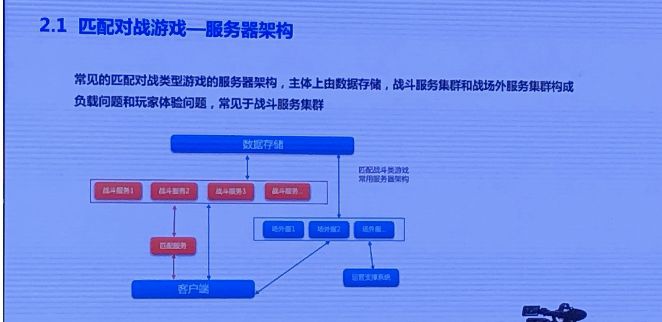
这是一个粗略且常见的匹配对战类型游戏的服务器架构,由数据存储、战斗服务集群和战场外服务集群构成。常见的负载问题和玩家体验问题,主要出现在战斗服务集群和玩家匹配服务两个部分。我把战斗服务和匹配服务标红了,这是我们今天需要讨论的,能否优化的重点地方。
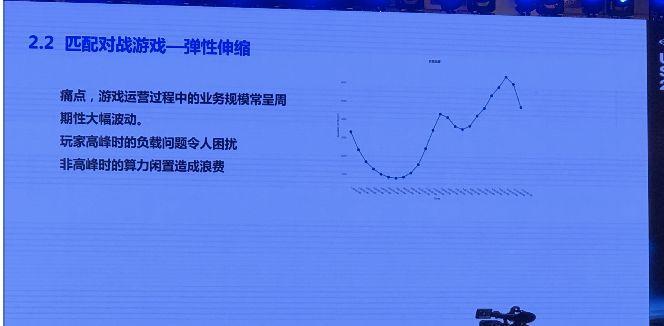
我们首先看痛点,下面这个图是某游戏在一天中,它的玩家活跃情况。我们可以看到,在凌晨五点钟左右的时候,基本上没有人玩游戏了,整个服务器是空置的。12点到1点左右有个小高峰,晚上10点11点,是游戏负载最高的时候。
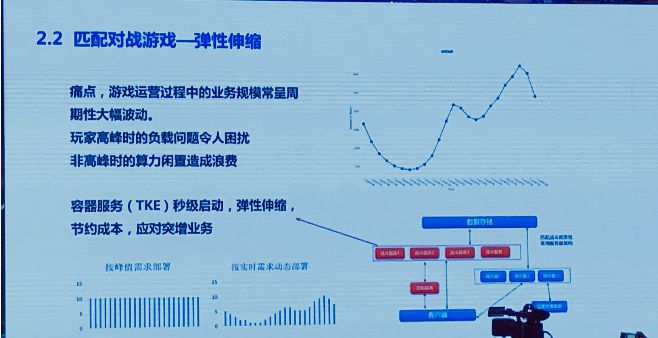
游戏过程中,业务规模通常呈周期性大规模波动。玩家高峰时期的服务器负载问题令我们困扰,非高峰时又是算力闲置造成浪费。
研究云服务提供的解决方案已经具备一定的可用性了,容器服务,比如说腾讯的TKE,秒级启动,弹性伸缩。我们可以在一天内按照小时根据我们的业务负载,动态的调整我们的集群实际数量,我们可以从图中看到,这样做下来的话,在一天中,和按需部署相比、按峰值需求相比,我们可以节省一半左右的数量。也可以通过云服务提供灵活部署的能力,给游戏的爆发性增长打下很好的算力提供基础。这是已经具备可用性的东西,是弹性伸缩的部分,大家感兴趣的话,可以再了解一下容器技术。
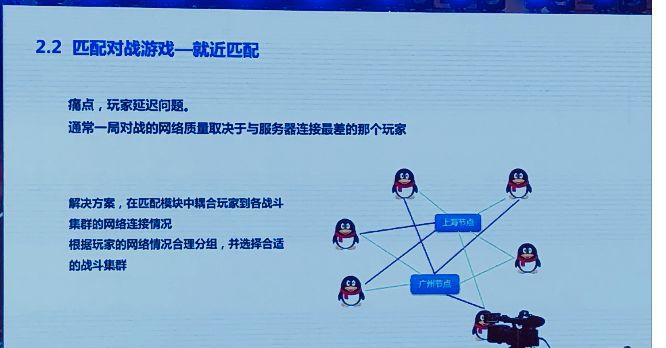
另外一个痛点,延迟问题。通常一局对战的网络质量取决于与服务器连接最差的那个玩家。有很多因素,通常是从游戏公平性考虑,我们不能过度惩罚网络连接度比较慢的玩家。还有同步架构的模式,我们如果选择帧同步方案,这个方案原理使得我们要等待连接最差的玩家把操作同步给其他玩家之后,才能把游戏时间线继续下去。
在这种情况下,如何才能进一步优化,让参加一局对战的所有玩家都更好的网络连接呢?我们考虑对匹配模块动手,匹配模块在传统架构中是一个纯业务模块,纯粹的游戏业务模块。在运维过程中,不会动到它。而我们考虑的另外一个信息是,玩家和我们的各个战斗服务集群之间的连接情况,这一块是一个相对偏云服务的数据,和我们的传统业务模块之间有着比较大的隔离。
如果我们把原本隔离较远的业务和数据耦合起来的话,我们会带来怎样的改变呢?举个例子,图中有6个玩家,已经初步经过了匹配。
我们的匹配系统通过他们的等级、战斗力或者近期胜率进行综合判断,觉得这几个玩家可以匹配在一起。同时,把他们分配到两场战斗中去,每场战斗三个人。我们在上海和广东节点都各部署了一批战斗集群,这时候按照传统的业务,6个玩家就实际分配了。
但是每个玩家到每个战斗集群的网络连接质量是不一致的,如果我们把这个信息在原本匹配完成的阶段,再进一步耦合进入我们的匹配逻辑,做进一步的优化,那我们可以根据图上的情况,为玩家做一个优化的分组。按照这样的分组,两组三个人的话,每个玩家都可以获得相对优秀的网络连接体验。
这块讲的就是在我们的匹配模块中,如果我们耦合一些由云服务这边提供的网络信息的话,我们有进一步优化玩家体验的空间。
结合我们前面刚讲过的弹性伸缩的问题,我们再来进行一个具有前瞻性的探讨,有没有可能把这两者结合起来?是否可以根据已经匹配成功的玩家的综合网络情况,选择合适的云服务节点,注意我说的是云服务节点,而不是我们预先部署好的战斗集群。这两者的差距就是选择范围的差距。像我们腾讯在各个地区有很多可用区,这些可用区,我们是否可以不预先铺设战斗集群呢?
我们在匹配完成之后,根据玩家的网络情况,选择合适的云服务节点,快速启动战斗服实例提供服务,战斗结算后,回收实例。就像下图这样,我们并不预先铺设战斗集群,玩家匹配成功之后,根据玩家的综合情况,我们选择最合适的云可用区,在可用区了,通过技术,进行战斗服务的秒级部署。这样可以进一步在有需要的地区,在网络情况最合适的地区,为玩家提供临时的战斗服务。服务结束后,我们还可以把实例回收掉。
这样的简单型架构,我个人相信随着行业的进一步成熟,我们技术的演进,是必然会被实现的。
这里我们简单讲了一下匹配对战这种游戏架构类型下我们的云服务可以进阶提供哪些东西。接下来我们讲一下连续大世界的架构,这是一个分布式计算的故事,首先我们了解一下连续大世界的需求。
如何提供给大家一个丰富精致而又连续的大世界?这是我们今天探讨的点。
假设在某MMO游戏里,模拟一个与地球表面尺寸相当的物理沙盒世界。有两个关键因素,首先与地球表面尺寸相当,然后有物理沙盒的元素存在,说明单位面积内的算力要求非常的高。在传统的MMO架构里,我们最有可能怎样做呢?我们可能会用一个场景服务器集群去不连续的描述这个世界,由不同的场景服务器负责的场景,模拟玩家在这样的世界中游玩的过程。
假设在游戏中举行一重大世界范围赛事,环世界火箭车拉力赛,参赛的玩家同时驾驶火箭车沿赤道环世界一周。玩家A最终获得了胜利,凭借他高超的游戏技巧,和顶级的个人电脑、网络配置,在整个比赛中行驶了10W公里。
我们想一下第二名追逐第一名的场景,两辆火箭车追逐,忽然前车从穿梭门消失了,后车也紧跟过去,然后显示了加载界面。我们连接另外一个服务器,完成后,第二名进入到新的场景,开始在新的场景继续追逐他,这样尴尬的体验肯定不是我们想提供给玩家的。造成这样问题的原因是,在模拟大场景时,如果有物理、AI等算力的高需求时,需要的计算量远超单台物理机所能提供的。
黑石2.0裸金属,80核384G,可以解决大部分的大世界需求。但是我们今天讨论的可能是需要一百台黑石才能解决计算的规模。
我们在设计一个方案的时候,第一步是设立方案的目标。
首先,要支持复杂计算,物理、AI、风或者火焰。然后,我们的世界要超大,这两者加起来就决定了一点,即我们的算力需求是远远超过单台设备或者若干台设备所能提供的。并且我们要求场景体验是无缝连续的,我们不希望玩家感受到这个世界是被割裂的,我们不希望玩家在区域之间切换的时候会加载,或者感觉到明显的卡顿。
这个体验分两部分,一个是服务端这边访问不同场景的服务器,另一个是客户端的动态加载。客户端的动态加载早在十几年前就已经很好的实现了。今天主要讨论的是服务端这块的架构。再追加一个需求,我们希望这个世界在扩展的时候是不需要停机维护的。
这个需求其实很好理解,我们创建一个很大规模虚拟世界的时候,通常不是一蹴而就的,我们会先开发好一些区域开放给玩家,然后不断迭代,开放新的区域给玩家。在这个过程中,我们希望新区域的开发和开放,不对旧区域造成影响。我们希望世界扩展不需停机维护。
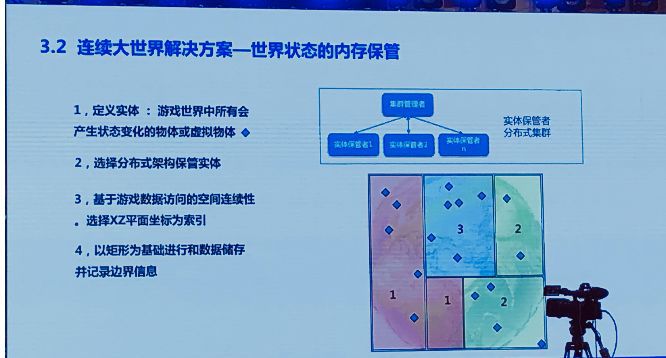
基于这些需求来设计我们的方案,首先,我们在虚拟一个世界的时候,我们先要描述它。换句话说,在我们的内存中保管状态。我们先要确定保管哪些数据,要做一个简单的对实体概念的定义。游戏世界中所有会产生状态变化的物体或虚拟物体,我们把它定义为一个实体的概念,一个我们自己定义的概念。这样的话,所有我们需要保存的内存数据,简单来讲,就是这个世界上所有实体的集合。
因为我们的世界很丰富,而且很大,所以所有的实体数据会是一个很大的尺寸,超出了单台物理设备的性能瓶颈,我们需要一个分布式的架构保管实体。
这是非常简易的分布式架构示意图。
分布式集群,主要由若干个实体保管者和一个集群管理者构成。对集群里某个实体的访问,比如我要访问集群里某个实体,我们先会询问集群管理者在哪里,集群管理者说在保管管理者2。只要集群管理者还承的住,那我们的数量就可以任意扩张,以达到我们对这个实体高数量的需求。
我们这里有个前提,就是我们的集群管理者没有崩。实际上在游戏具体应用场景里,游戏实体在游戏过程中,是频繁发生大规模的状态改变,在这样频繁的访问情况下。如果每次数据访问都通过集群管理者问一下的话,它很快就撑不住了,这个架构负载是非常有限的。我们这里首先要做一个简单的大面上的优化,确保我们的性能在需求的数量级范围之内。
我怎么做呢?可以针对我们保管的数据特性采取措施,我们保管的数据是实体,是世界中的实体。世界中的实体有怎样的构成特性呢?大家可以想一下Unity里的每个object都有怎样的公共组件?transform。所以每个实体,不管他是虚拟物体还是真实存在的物体,在这个世界中都有它自己的方位。
同时,游戏中的各种事物,无论是物理还是AI,对这些实体的访问都具备什么特性呢?空间连续性。我们基于数据访问的空间连续性,我们选择以XZ平面坐标为索引。空间连续性我解释一下,打比方说刚体物理碰撞的事物来讲,一个刚体能碰撞了,能碰撞到其他刚体,很显然是能跟他接触的刚体。如果换作AI例子里面呢?一个AI巡路的时候,他需要读取的数据一定是在AI个体的视野范围内,不可能读地球对面另外一个实体的数据。这样,数据访问的连续性引导下,我们以XZ平面的矩形为基础,进行数据的存储。
我们把这块区域切分成了5个矩形,这5个矩形分别存在在三个实体管理者里面。
当我们去访问蓝色矩形里的一个实体时,我们先询问实体管理者这个实体在哪儿,完成这次访问之后,下一次访问极有可能还是在蓝色矩形之内,我们就不需要再访问集群管理者。下一个访问实地,可能超过了3号蓝色矩形边界的话,也极有可能就在他邻居的矩形之内,我们知道边界方向在哪边,这也就是我们为什么以矩形为基础进行数据存储的同时,记录边界信息。这些操作之下,我们会大大减少对集群管理者的访问,也就拓展了我们分布式架构的数据容量,基本上满足我们的需求。
这时候我们解决了数据的保管,我们还要做一些什么事呢?首先,因为我们是基于实体的位置做保管,实体的位置会在游戏中进行改变,我们要做一个实体在保管者之间移动,这是架构的需要。当一个实体从一个矩形移动到另外一个矩形的时候,我们需要他在实体保管者间的迁移,这需要在比较短的时间,比如说在一帧之内进行迁移,这样不会对玩家体验造成伤害。
我们还需要做什么?我们要做保管者保管范围的扩所。举一个具体的例子,我们这边有三个实体保管者,我们要针对1号保管者所在的物理机器做一个升级,暂时下线。我们怎么做?
首先看1号保管者管着的两个矩形小一点的矩形已经没有任何实体了,非常好操作,我们可以在比较短的时间把这个小矩形划分到2号管理者的保管范围之内,2号保管者可能把这个矩形和自己保管的矩形合并一下。1号保管者还有一个大矩形,里面有若干实体,实体比较多的时候,我们无法在短的时间内完成数据的迁移。
我们可以把这个矩形与我们需求内的时间片,从这个大矩形中切一片小矩形下来,持续这样做,直到我们把1号实体保管者所有的负载迁移完毕,就可以做硬件升级了。再启动上来,逆转刚才的过程,把自己需要承担的负载再承担起来。我们做完这件事之后,就实现了这个集群的弹性收缩,同时还有这个集群的负载均衡。
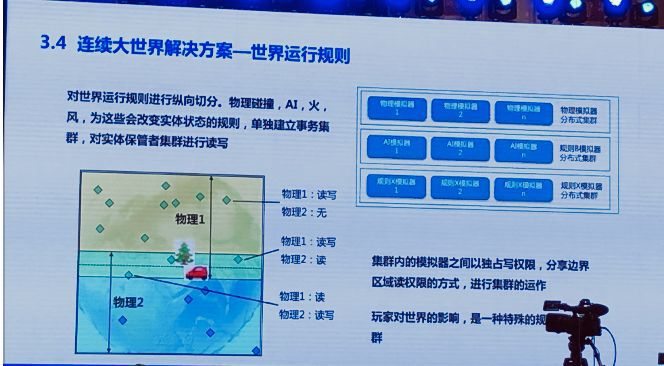
这个世界被我们保管起来了,我们剩下的事就是让这个世界动起来,建设世界运行规则。首先我们对世界运行规则进行纵向切分,比如说物理碰撞、AI、火焰和风,根据计算特性的纵向切分。然后我们针对每个切分出来的功能,每个切分出来的规则,单独建立一个事物集群,对实体保管者集群里存储的实体数据进行读写。
可以看到图中是一个大的集合,这个集合里是若干个纵向切分出来的模拟,他们分别组成模拟器分布式集群。
这个集群里,每个集群的组成方式和之前我们说的实体保管集群类似。我们都是通过方块、矩形进行一个边界的管理。这里拿物理的模拟器举个例子,这里的边界管理是和实体的储存编辑管理有区别的。简单来讲,我们需要一个双重边界,一个写边界和读边界。写边界的操作就和实体的主动管理是一致的,就是管者把整个场景切分成若干个互不重复的矩形,交给不同的物理模拟器管理。读边界需要比矩形的写边界更加大一圈,这样保证他们协同工作。
怎么工作呢?举个例子。这个区域有两个物理模拟器协同工作,他们各负责了上下一个矩形,那么中间的虚线是他们写边界的分界线,两条实线分别是他们读边界的分界线。我们可以看到他们的读边界互相有一定的重合范围。这时,我们在物理模拟器1所负责的场景内,靠近边界的地方有一颗树,是一个刚体。这个刚体对于物理1来讲,物理1用了这棵树的读权限和写权限,而物理2只拥有读权限。这时候一辆车开过来撞到这颗树,碰撞发生的时候,这个车的权限和树相反,物理2拥有这辆车的读写权限,而物理1只有读权限。
这是怎么发生的呢?首先站在物理1的角度,物理1具有树和车两者的读取权限,换句话说,他有完整的碰撞现场。物理1可以得出一个结论,树被撞倒,车停下来。但是物理1无法让车停下来,只能让树倒下。物理2与物理1相反,物理2也知道,也有完整的碰撞现场,知道树应该倒下,车应该停下来。但是物理2只能让车停下来,不能让树倒下,那就各做各的事嘛。
简单讲,每个模拟器在自己的读边界内会拥有一个完整碰撞现场的数据,能够推导出一致的碰撞结果。同时他们做写入操作的时候,只做写权限那部分的事情。这样使我们的若干模拟器以集群的方式在一起工作,而集群的方式,优点我们讨论过,可以实现负载平衡的,最重要的一点可以跨越不同的物理设备。
换个例子,在AI的情况下,和物理情况会有什么不同呢?大面上讲只有一点不同,我们对于读权限的边界,要比写权限边界大多少?在刚体碰撞的例子里面,读权限的边界,大概只需要比写权限大多少的距离呢?这个距离只要略大于我们世界中最大的刚体尺寸,差不多效果不错了。对于AI来讲,多出的距离,可能会是一个实体的最大视野范围,这可能看具体的情况,怎样的逻辑才能顺利的进行。
我们搭建这样一个关于运行规则的模拟器集群大结合之后,还剩下一件事,就是玩家的操作。事实上,玩家对世界的影响其实也是一种特殊规则的模拟器集群,想象一下,和物理集群一样,我们创造一个接受全世界各地玩家的操作,并且处理相关事务的一个模拟器集群。里面每个模拟器会负载一定量的玩家连接,包括对玩家的操作,去对这个世界上的实体进行读写。他和其他模拟器集群的唯一区别,就是它会读取玩家的操作,作为自己规则模拟计算的一部分。
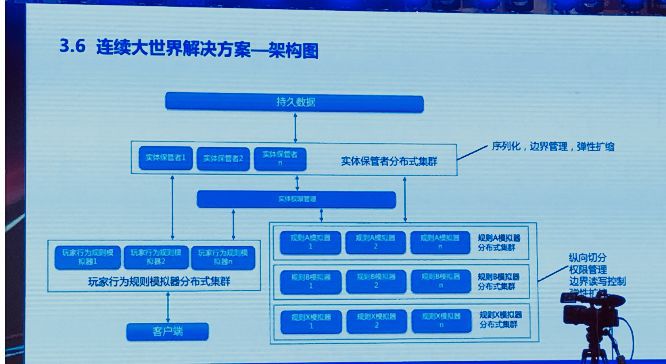
简单分成这两步,第一步把世界描述出来,第二步建立一个集群把世界运行起来,这样一个连续大世界就被我们运作出来了。我们看一下完整的架构图,由几个集群构成,首先是我们创建的实体保管者分布式集群,支持序列化、边界管理和弹性扩缩。然后由一个大的规则模拟器集群组成的世界规则运行的集合,这个集合首先做了一个纵向切分,然后做相关读写权限管理,做了边界读写控制,同时里面每个集群也都支持弹性扩缩。同时,在玩家行为模拟这边,运作方式是和世界规则模拟器这边非常类似的,唯一的区别只是它会接受玩家的操作作为自己规则计算的一部分。
按照这个架构,我们可以满足我们之前定下来的四条标准,能够超越单个物理设备的运算瓶颈。我们期待在玩家可以接受的用户体验下,让他们感觉到整个世界是连续的,而且这个世界可以动态扩展。这就是关于连续大世界的解决方案。
讲一点个人的感想,我个人做游戏十几年,客户端、服务端,包括制作人都做过。云计算时代来讲,我个人最深的一点感受,集中在三个字:分布式,把我们的代码写成分布式的形式,利用云去部署我们的分布式代码,帮助它脱离硬件的性能,以及硬件的故障束缚。
来源:游戏葡萄






 Steam
Steam  App Store
App Store 

















 闽公网安备 35020302034348号
闽公网安备 35020302034348号